Расшифровка водительского удостоверения нового образца: отметки, категории | 🚗YAVMASHINE.RU
С начала 2014 года в России введены в действие водительские права нового образца. Сделаны они теперь из пластика, и как во всех уважающих себя странах, оснащены повышенной степенью защиты и имеют полное соответствие международным стандартам.
В связи с этим, у людей возникает множество вопросов: какая информация должна отражаться на документе, что означают категории и подкатегории транспортных средств, какие элементы защиты от подделок содержит новое удостоверение и так далее. Ответы на все вопросы можно найти, прочитав статью.
Отличия старого удостоверения от нового
Главные изменения прав для вождения коснулись не только внешнего вида документа и усложнённой схемы защиты. В связи с введением новых «пограничных» категорий, обновилось и содержание удостоверения водителя.
По внешнему виду
Одно из главных различий — материал. Если раньше права оформлялись на плотной бумаге, которая затем ламинировалась, то самые современные водительские удостоверения представляют собой кусочек пластика.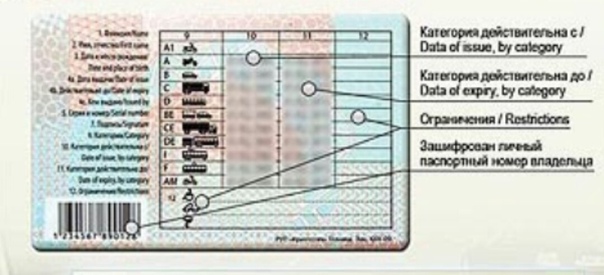
Система защиты
Поскольку главный бич любых мало-мальски важных документов — возможность их подделать, а спрос всегда рождает предложение, новые права оснащены высококачественной системой защиты.
Поэтому на данный момент подделка их невозможна, а сами удостоверения соответствуют самым высоким требованиям международных стандартов.
Так, тыльная сторона удостоверения снабжена сложным узором (подобно узору на денежных купюрах), а также голографическими знаками.
Расшифровка категорий
Информационная сетка на оборотной стороне прав для вождения предусматривает наименование категорий и подкатегорий, а также «иконки» — схематические обозначения различных видов транспорта, на который можно получить право управления после обучения и сдачи экзаменов. Рассмотрим их по порядку.
Легковой автомототранспорт
Прежде легковые личные транспортные средства делились на автомобили и мототранспорт, и существовало всего две категории – А и В. Теперь же подгрупп стало несколько.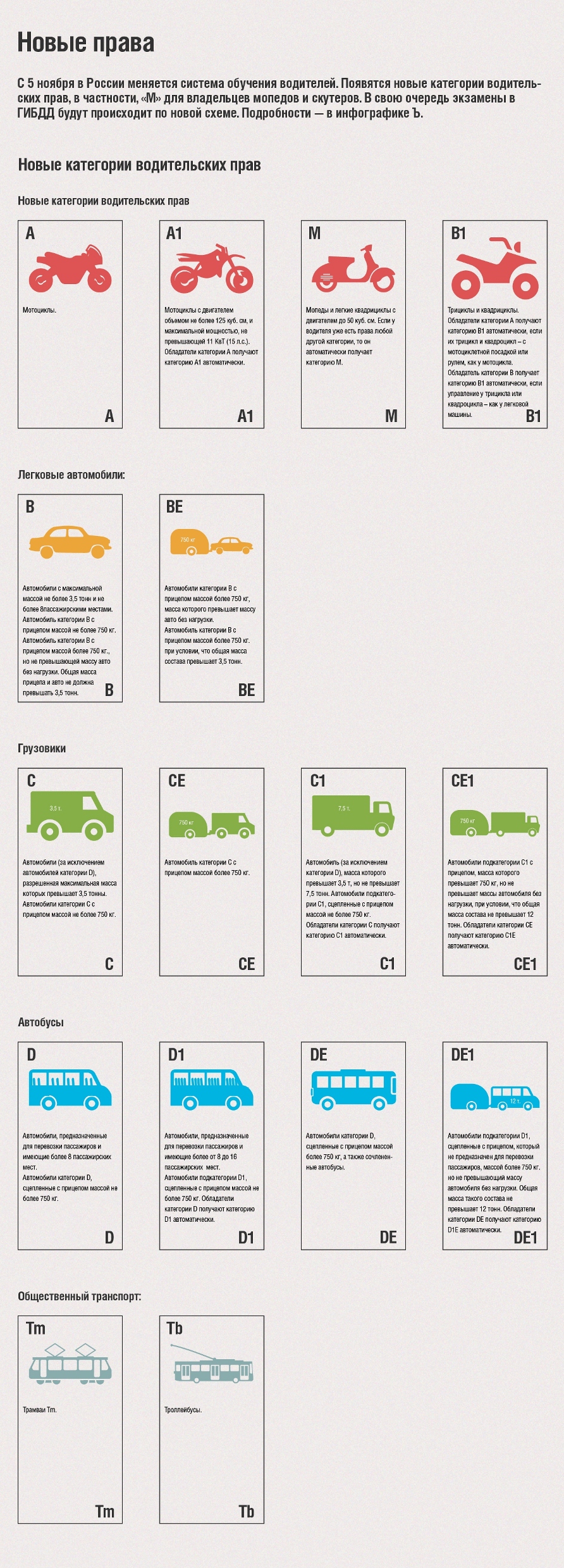 В зависимости от таких показателей, как объем движка, габариты или масса автомобиля, легковой автомототранспорт делится на следующие категории:
В зависимости от таких показателей, как объем движка, габариты или масса автомобиля, легковой автомототранспорт делится на следующие категории:
«А» даёт право управления тяжелыми мотоциклами с двигателем объемом свыше 125 куб.см.
«А1»: сюда относятся облегчённые мотоциклы с объемом двигателя до 125 куб.см.
«В»: самая распространённая категория. Ее обладатели могут водить легковые автомобили массой не более 3,5 тонн. Число пассажиромест не должно превышать восьми.
«В1»: трициклы и квадрициклы, не имевшие раньше собственной категории, теперь выделены в отдельный тип транспорта. Причём следует заметить, что получить возможность управления подобным транспортом могут и обладатели базовых категорий «А» или «В» — в зависимости от типа рулевого механизма.
Автомобили категории «ВЕ» — «легковушки», имеющие прицеп с общей массой свыше 750 кг.
«М»: мопеды, скутеры и квадроциклы с двигателем объемом до 50 куб.см. У всех обладателей иных категорий, окончивших автошколу, автоматически открыта категория «М». До недавнего времени на дорогах серьезную конкуренцию легковым автомобилям создавали подростки и молодежь на мопедах.
До недавнего времени на дорогах серьезную конкуренцию легковым автомобилям создавали подростки и молодежь на мопедах.
Поскольку езда на этом виде транспорта раньше не требовала специальной подготовки или наличия правоподтверждающих документов, водители мопедов часто становились участниками ДТП, порой сами эти аварии и инициируя.
С введением обязательного обучения в автошколе и сдачи экзамена на право управления, количество мопедов на дорогах резко сократилось, равно как и количество дорожно-транспортных происшествий с участием этого вида транспорта.
Грузовые автомобили
В дополнение к имевшимся категориям для грузовиков также были добавлены промежуточные.
«С»: в эту категорию выделены грузовики общей массой свыше 3,5 тонн и прицепом не тяжелее 750 килограмм
«С1»: сюда относятся грузовые автомобили массой от 3,5 до 7,5 тонн. Кроме того, категория дает возможность оснастить грузовик прицепом массой не более 750 килограмм.
«СЕ» позволяет управлять грузовым автотранспортом с прицепом, масса которого превышает 750 килограмм (но не более 3,5 тонн).
«С1Е»: к отдельной категории относятся тяжелые грузовики с прицепом и совокупной массой сцепленного состава до двенадцати тонн.
Пассажирский транспорт
«D»: права этой категории дают возможность управления автобусами с числом мест для пассажиров от шестнадцати и больше.
«D1»: в категорию выделены небольшие автобусы (микроавтобусы) с числом сидячих мест от восьми до шестнадцати (не считая сиденья водителя).
«DE»: категория для автобусов массой 750 – 3500 килограмм с прицепом. Сюда относятся сочлененные автобусы (с «гармошкой»).
«D1E»: категория даёт право управления небольшими автобусами с числом пассажиромест от 8 до 16 с прицепом (прицеп не разрешен для перевозки пассажиров).
«Tb» даёт право водить троллейбусы.
«Tm»: для управления трамваем.
Таким образом, к 2018 году категории водительских удостоверений, дающих право управления различными видами наземного транспорта претерпели эволюцию от пяти типов (A и B для любителей; C, D, E для профессиональных водителей) до сложной схемы с различными подвидами.
Штрихкод на водительском удостоверении расположен слева на обратной стороне.
Код содержит в зашифрованном виде максимум информации о владельце. Поле размером 10х42 мм предназначено для автоматизированной идентификации.
Многие водители интересуются, что значит двойная запись выдачи водительского удостоверения? Такой ответ часто выскакивает при проверке ВУ, полученного неофициальным способом. Скорее всего, мошенники подсунули чей-то дубликат, то есть сделали права-двойники. Так вот, проверка по штрихкоду в ГИБДД позволяет развеять сомнения в подлинности прав.
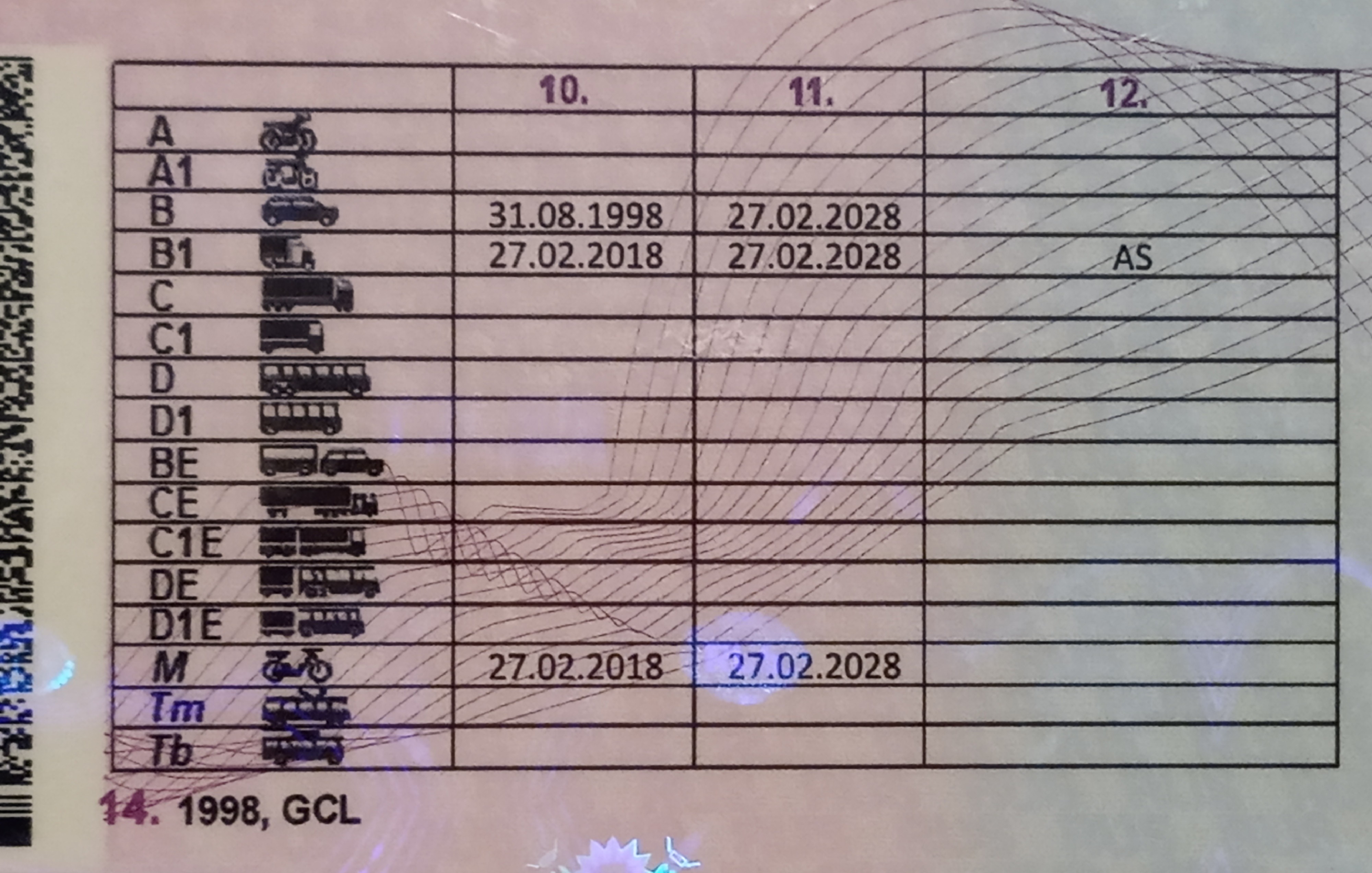
Справа внизу ВУ находится серия (четыре цифры) и номер (шесть цифр), напечатанные красной краской. Почти вся обратная сторона водительского удостоверения занята таблицей с четырьмя столбцами.
В первом указаны все возможные категории и пиктограммы соответствующих им ТС. Во втором (графа 10) указана дата открытия, а в третьем (графа 11) – дата прекращения действия. В последний столбец (графа 12) вносятся ограничения. В графу 14 под таблицей заносится информация общего характера, касающаяся всех без исключения категорий.
В последний столбец (графа 12) вносятся ограничения. В графу 14 под таблицей заносится информация общего характера, касающаяся всех без исключения категорий.
Категорически не рекомендуется игнорировать особые отметки, особенно ограничивающие право управления. Данные водительского удостоверения легко проверяются, а в ПДД предусмотрены серьезные штрафы за несоблюдение требований. Чаще всего это рассматривается как езда без прав
Зачем в правах нужны особые отметкиЕсли в старых правах была одна строка для особых отметок, то в новых – сразу две. Зачем это сделано и что означают особые отметки в водительском удостоверении (ВУ)? Очевидно, что для предоставления большего объема информации сотрудникам Госавтоинспекции и водителям об их возможностях.
Особые отметки устанавливают ограничения на открытые ранее категории или на водительское удостоверение в целом в зависимости от разных причин.
Начнем с того, что означают цифры на водительском удостоверении? Это серия и номер ВУ. Также цифрами обозначены графы или пункты для заполнения. Их всего четырнадцать.
Также цифрами обозначены графы или пункты для заполнения. Их всего четырнадцать.
Некоторые наши водители интересуются, на каком языке дублируются надписи на новых российских водительских правах. Часть записей повторяется на английском: это имя и фамилия обладателя документа, место проживания и название органа, выдавшего ВУ.
Полная расшифровка пунктов водительского удостоверения нового образца будет дана далее.
Какие отметки могут бытьУсловно все отметки в удостоверении можно разделить на обязательные и особые. В прямом смысле «обязательных» нет, просто существует единая узаконенная форма заполнения. Их можно встретить в любом ВУ. На лицевой стороне (даны по пунктам в удостоверении):
- Фамилия владельца.
- Имя.
- Место и дата рождения.
- Даты выдачи и окончания действия, подразделение ГИБДД, выдавшее документ (буквенное и цифровое, включающее четыре знака).
- Номер и серия ВУ.
- Место для фото.
- Подпись собственника.

- Регион проживания.
Эти сведения всем понятны и не вызывают лишних вопросов. А вот второй вид отметок часто ставит в недоумение автолюбителей. Они так и называются особыми, потому что используются в особых случаях. Причем относиться они могут к отдельным или ко всем категориям сразу. Поэтому ставятся в разные графы: 12 или 14. Благо в новых правах две строки для особых обозначений. Итак, рассмотрим, какие особые отметки ставят в водительском удостоверении.
Что значит GCLЭта отметка относится к числу самых загадочных. Что означает отметка GCL в водительском удостоверении, интересует многих автовладельцев. А она указывает, что водителю разрешено управление лишь при использовании приборов коррекции органов зрения (очков/линз).
Требование основывается на диагнозе окулиста, заключение которого дается в медицинской справке. GCL заносится в 14-й пункт в водительском удостоверении. На фотографии в правах такой водитель должен быть в очках или с линзами, даже если последнего видно не будет.
Если имеются ограничения по медицинским показаниям или в справке отсутствует указание на разрешение управлять такой техникой, в разделе 12 напротив категории ставят особую отметку ML. Что означает отметка ML в водительском удостоверении? Она подтверждает наличие медицинских ограничений и фактически запрещает управление транспортными средствами данной категории.
Отметка ASAS ставится в графе напротив категории В1 (при закрытой категории А) и допускает к управлению транспортными средствами исключительно с автомобильным управлением и посадкой.
Подробно тема раскрыта в статье «Что означает AS в правах».
Отметка ATОтметка АТ в водительском удостоверении обозначает, что его владелец допущен к управлению ТС исключительно с автоматической трансмиссией. Механическая коробка для него табу. Ограничение связано с тем, что водитель обучался и сдавал экзамен на машине с АКПП.
Медицинские ограниченияБольше всего особых отметок относится именно к этому типу. И неспроста. Сегодня ездить имеют право почти все, пусть даже и с ограничениями по здоровью. Особые отметки в водительском удостоверении вносятся, когда медицинская справка обязательна. Ставят их в графе 14:
И неспроста. Сегодня ездить имеют право почти все, пусть даже и с ограничениями по здоровью. Особые отметки в водительском удостоверении вносятся, когда медицинская справка обязательна. Ставят их в графе 14:
- «Медицинская справка». С такой отметкой ВУ действительно при наличии действующей медсправки. Ограничение устанавливается при выявлении проблем со здоровьем, требующих постоянного контроля. Это могут быть болезни сердца или некоторые другие, не имеющие ярко выраженных проявлений. Другими словами, ездить можно, но со справкой.
- Отметка MC говорит о разрешении управлять ТС с ручным управлением, и только таким. Как правило, это касается людей с ограниченной двигательной функцией (инвалидов). Ставится после переоборудования на основании вывода медкомиссии.
- APS означает, что обладатель ВУ допущен к управлению автомобилем исключительно с автоматической системой парковки.
- HA/CF – водителю разрешено управление ТС только при условии ношения слухового аппарата.

Об особой отметке в водительском удостоверении, требующей ношения очков и линз, мы уже сказали ранее. Она тоже обязывает водителя возить с собой медсправку.
Помимо этого, предусмотрена возможность поставить в 14-ю графу отметку о группе крови, чем многие пользуются. Она не убережет от ДТП, но в некоторых случаях может спасти жизнь водителя.
Другие меткиТакже в ВУ могут встречаться следующие отметки:
- MS. Если такая стоит в 12 графе водителю разрешается управлять ТС с посадкой и рулем мотоциклетного типа.
- Дубликат. Отметка ставится при замене ВУ по причине утраты или хищения.
- Стаж водителя. Отметка ставится при замене ВУ для индикации года получения первого удостоверения.
Класс водительского удостоверения определяется, как и ранее: перечнем открытых категорий и стажем работы. Но в самом удостоверении он нигде не указывается.
Как видим, расшифровка пунктов водительского удостоверения нового образца 2019 года не представляется чересчур сложной.
Действительны ли права старого образца
Десять лет — немалый срок, особенно, когда речь идёт о законодательстве. Оно постоянно претерпевает метаморфозы, в том числе, и относительно документации. И зачастую ламинированные права, полученные автомобилистом в 2009, например, году, остаются у него на руках, в то время как большинство водителей уже получили удостоверения нового образца.
Начиная с 2014 года водительское удостоверение старого образца окончательно упразднено и больше не выдается.
Заключение
За последние полтора десятка лет водительские права претерпели массу изменений. Трансформировался не только материал, из которого они изготавливаются. Выход новых законов и правил, связанных с безопасностью дорожного движения, внес свои коррективы и в главный документ водителя.
Введены новые промежуточные категории, описывающие те виды транспорта, которые раньше было сложно выделить в один тип. Цель всех этих изменений – наиболее полно отражать информацию об участниках дорожного движения во избежание опасных ситуаций.
Развитие современных технологий дало свой отпечаток на электронной защите удостоверения от подделывания, а значит, вполне вероятно, что и действующий образец прав на вождение далеко не последний.
Категории водительских прав: расшифровка новых категорий
Водительские права выдаются в соответствие с категорией транспортных средств. В зависимости от категории различается программа подготовки, которая может быть освоена в автошколах и на занятиях с автоинструкторами в Москве и других городах. Федеральный закон «О безопасности дорожного движения» от 10 декабря 1995 года № 196-ФЗ устанавливает следующие категории транспортных средств.
Категория А. К ней относятся автотранспортные средства следующих видов: классические мотоциклы, спортбайки, круизеры, эндуро, скутеры (мотороллеры) и т. д. Критерием выделения служит максимальное значение снаряженной массы транспортного средства, равное 400 кг. Получить водительское удостоверение с пометкой А можно при достижении возраста 16 лет. Программа обучения включает теоретический курс объемом 105 часов, практические занятия общей продолжительностью 50 часов.
д. Критерием выделения служит максимальное значение снаряженной массы транспортного средства, равное 400 кг. Получить водительское удостоверение с пометкой А можно при достижении возраста 16 лет. Программа обучения включает теоретический курс объемом 105 часов, практические занятия общей продолжительностью 50 часов.
Категория В. В нее входят легковые, малые грузовые и грузопассажирские автомобили снаряженной массой не более 3500 кг и количеством пассажирских мест не более 8. В настоящее время регулярно повышается доля машин с автоматической коробкой передач (в 2012 году она составила 41%), что влияет на популярность услуг автоинструкторов на АКПП и других городах. Обучение состоит из тех же разделов, что и при получении прав класса А. Водительское удостоверение категории В выдается гражданам, достигшим возраста 18 лет.
Категория С включает в себя грузовые автомобили максимальной разрешенной (снаряженной) массой более 3500 кг. При обучении реализуется полный теоретический курс в объеме 105 часов и проводятся практические занятия суммарной длительностью 50 часов.
Категория D. Включает пассажирские автобусы с количеством сидячих мест более 8, помимо места водителя. Программа обучения включает теоретический курс (119 часов) и практические занятия (37 часов). Получить права на управление автобусами можно с 20 лет.
Категория Е подразделяется на «В к Е», «С к Е», «D к E». В сочетании с основными классами она дает право управления легковым, грузовым или грузопассажирским автомобилем с прицепом массой свыше 750 кг. Права Е выдаются лицам, имеющим права основной категории (В, С или D) при наличии стажа вождения более 12 месяцев.
Что означает отметка «AS» на водительских правах?
Водительские удостоверения после редакции пополнились новыми обозначениями. При этом довольно больше количество водителей не имеют ни малейшего понятия о том, что они значат. На обратной стороне заветной ламинированной картонки сохранились записи о доступных категориях транспорта, но также там теперь красуются и другие буквы, а именно «AS», «AT», «MS». Что же скрывается за этими аббревиатурами?
Что же скрывается за этими аббревиатурами?
Для начала стоит сказать, что подобные обозначения стали появляться в водительских правах, которые были выданы после 2014 года. В незапамятные времена, когда их не было, могла возникнуть небольшая путаница. Теперь же при первом получении прав или при замене уже имеющихся ставится обозначение подкатегории.
Начнем по порядку и с самого простого. Аббревиатура «АТ», что вполне логично, расшифровывается как «автоматическая трансмиссия». Например, если в правах указана категория «В» с пометкой «АТ», это значит, что владелец документа может управлять только легковым автомобилем с автоматической коробкой передач и при взаимодействии с «механикой» у него могут возникнуть сложности. При этом стоит помнить, что во время обучения он проходил курс, который специализировался именно на езде с «автоматом». И в случае, если сотрудник ГИБДД «поймает» его на вождении автомобиля с МКПП, может быть выписан штраф.
Обозначение «MS» ставится на права в случае, когда их владелец может управлять транспортом с мотоциклетной посадкой и рулем. Естественно, при наличии и соответствующей категории. Говоря простым языком, это значит, что владелец прав может управлять мототехникой.
Естественно, при наличии и соответствующей категории. Говоря простым языком, это значит, что владелец прав может управлять мототехникой.
Но вот самым частым обозначением, которое может красоваться на обратной стороне водительского удостоверения, являются буквы «AS». Они говорят о том, что водитель, в отличие от предыдущего пункта, не может управлять техникой с мотоциклетной посадкой и рулем. Например, если у него открыта категория «В», то он может без проблем управляться с автомобилем, но вот транспорт вроде квадроциклов, где отсутствует обычный прямой руль и спинка, для него под запретом. Но если транспорт является представителем семейства мототехники, при этом имея знакомый всем круглый руль и спинку, то управлять им можно.
Фото с интернет-ресурсов
Об отметке AS в водительском удостоверении
Хотя водительские удостоверение нового образца начали выдавать еще с 2011 года, до сих пор некоторые обозначение в документе вызывают у автовладельцев вопросы.
Новые отметки в правах образца 2014 года
Речь об обозначениях, которые появились наряду с другими изменениями в новой форме документа. Карточка получила не только розово-голубой цвет, но на обратной стороне появились и новые категории, которые введены были уже в 2013 году:
- М (мопед), Tm (трамвай), Tb (троллейбус),
- подкатегории А1, В1, С1, D1, С1Е, D1Е.
После появления новых прав автомобилисты с категориями А и В обнаружили, что графа 12 AS в водительском удостоверении присутствует и у них. Аббревиатура означает ни что иное, как 
Расшифровка аббревиатуры AS в правах нового образца
О том, что обозначает отметка AS в водительском удостоверении, следует рассказать подробнее. Если с категориями все более-менее ясно и вопросов по ним у автомобилистов не возникает, то особые отметки мало о чем могут сказать рядовому автовладельцу. Объяснение очень простое. AS означает, что управлять автовладелец вправе только тем транспортом, у которого есть рулевой тип управления, то есть обычный автомобильный руль. Это не дуга и не иные механизмы управления наподобие мотоциклетных.
Иногда возникают интересные ситуации, когда автомобилисты с закрытой категорией А рядом с категорией водительских прав B1 видят рассматриваемую пометку и не могут предположить, что означает AS в водительских правах. Означает это только следующее — автовладельцу разрешается управлять мотоциклами и трициклами, оснащенными исключительно рулевым типом управления. Допускается и управление двухколесными ТС, тип посадки в которых автомобильный.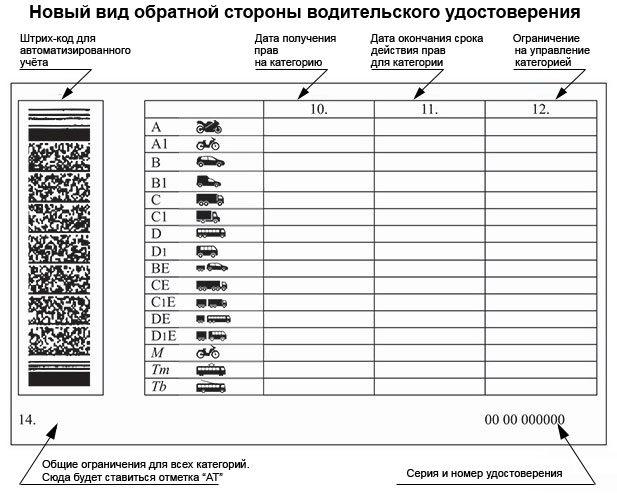
Что означают другие особые метки на водительском удостоверении — читайте в статье здесь.
Что означает пометка MS в правах
В 12 пункте в водительском удостоверении AS не всегда присутствует, но вместо него иногда печатается аббревиатура MS. Ее у себя в правах обнаруживают мотоциклисты, у которых открыта категория А или А1. Она расшифровывается как Motorcycle Steering. В переводе это означает мотоциклетное рулевое управление. С такими правами управлять можно только двухколесными ТС с мотоциклетным рулем и соответствующей посадкой.
Также важно, что отметка MS в правах ставится только тем мотоциклистам, у которых открыта водительская категория либо A, либо A1. Если действуют обе категории, то отметка MS в водительском удостоверении присутствовать не будет.
Остались вопросы? Задавайте их в комментариях
Расшифровка категорий водительских прав | Пдд онлайн
Здравствуйте, уважаемый автолюбитель!
Из этой статьи вы узнаете, какое отношение имеют категории водительских прав к автомобилям или на какие категории подразделяют транспортные средства.
Например, если вы хотите управлять мотоциклом, то и права должны быть с открытой категорией на право управления мотоциклами. Если хотите управлять легковым автомобилем, категория должна быть соответствующая — на право управления легковыми автомобилями. А для грузовиков и автобусов идут уже отдельные категории. Ну а теперь давайте приступим к расшифровке категорий водительских прав.
Категории водительского удостоверения обозначаются латинскими буквами. И самая первая категория начинается с первой буквы алфавита — A!
Категория A
Водительское удостоверение с отметкой «категория А» — подтверждает наличие права на управление мотоциклами, мотороллерами и другими мототранспортными средствами. Давайте обратимся к общим положениям ПДД, там написано, что «Мотоцикл» — двухколесное механическое транспортное средство с боковым прицепом или без него. К мотоциклам приравниваются трех- и четырехколесные механические транспортные средства, имеющие массу в снаряженном состоянии не более 400 кг.
Также имеется подпункт категории А, используемый для обозначения мотоциклов, количество которых не превышает 15 лошадиных сил. У таких мотоциклов, объем двигателя не превышает 125 см3. И использование таких мотоциклов разрешено с 16-ти лет.
Итак, категория «A» разрешает управлять мотоциклами.
Категория B
Водительское удостоверение с отметкой «категория В» — подтверждает наличие права на управление автомобилями, разрешенная максимальная масса которых не превышает 3500 килограммов и число сидячих мест, помимо сиденья водителя, не превышает 8. То есть вы можете управлять легковыми автомобилями, джипами и небольшими микроавтобусами. Но их разрешенная максимальная масса не должна быть более 3,5 тонн и число сидячих мест не должно быть более 8-ми, иначе это уже категория «C» или «D».
В дополнение, существует категория B1 описывающие транспортные средства с мотоциклетным мотором, массой не превышающей 550 кг и объемом двигателя до 50 см3.
С данной категорией вы можете подцепить прицеп к вашему автомобилю. Но разрешенная максимальная масса прицепа не должна превышать 750 кг, иначе это уже категория «E». Кроме этого, вам можно управлять мототранспортом масса которого превышает 400 кг.
Итак, категория «B» разрешает управлять легковыми автомобилями.
Категория C
Водительское удостоверение с отметкой категория «С» — подтверждает наличие права на управление автомобилями, за исключением относящихся к категории «D», разрешенная максимальная масса которых превышает 3500 килограммов. Эти автомобили называются грузовики. Но опять же, число сидячих мест, помимо сиденья водителя, не должно превышать 8. Так же как и в категории «B», вы можете подцепить прицеп с разрешенной максимальной массой не более 750 кг.
Подпункт категории С, который применяется к грузовым транспортным средствам общей массой от 3500 до 7500кг, обозначаемой категорией С1.
Категорией CE обозначается грузовой транспорт с прицепом, весом не более 750 кг.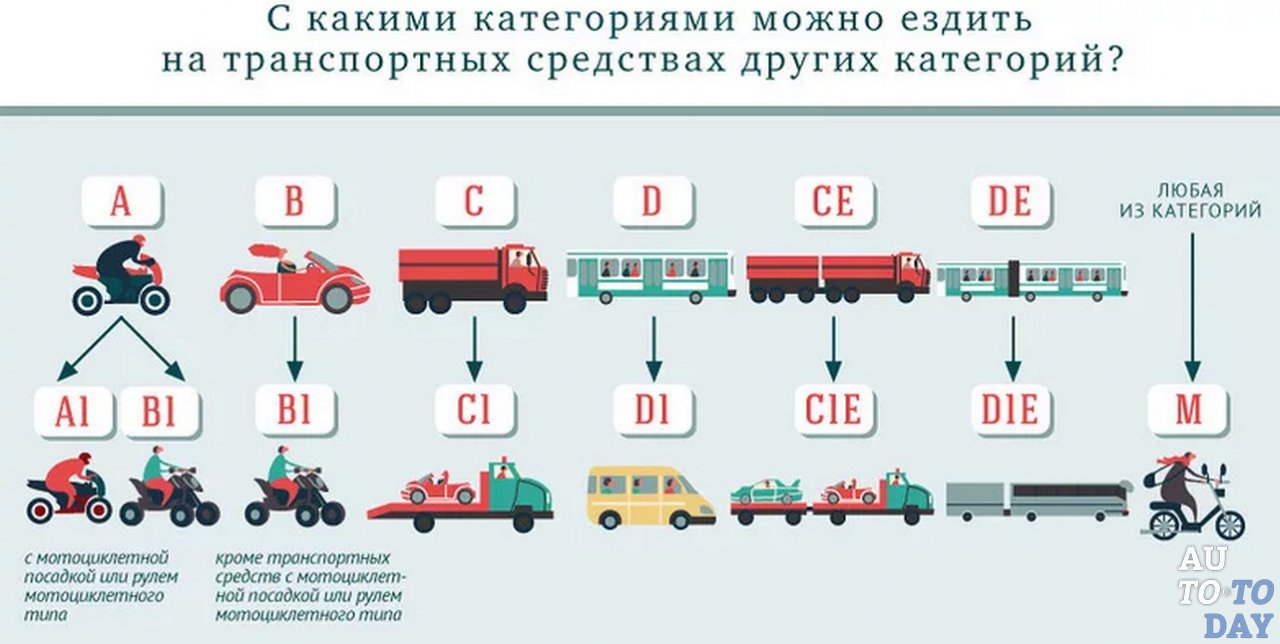
И, в завершение, категорией C1E обозначается грузовой транспорт с прицепом, массой от 3500 до 7500 кг.
Итак, категория «C» разрешает управлять грузовыми автомобилями.
Категория D
Почитав предыдущие категории, вы уже поняли, что категория Д напрямую зависит от количества сидячих мест в транспортном средстве. Водительское удостоверение с отметкой категория «D» — подтверждает наличие права на управление автомобилями, предназначенными для перевозки пассажиров и имеющими более 8 сидячих мест, помимо сиденья водителя. То есть с категорией Д вы можете управлять любыми автобусами, причем не зависимо от разрешенной максимальной массы. И опять же, вы можете прицепить к автобусу прицеп, но с разрешенной максимальной массой не более 750 кг, иначе это уже следующая и последняя категория Е.
Также, имеется категория D1 описывающие автобусы малой вместимости, с количеством сидячих от 8 до 16 мест.
И, есть категория D1E применяющаяся к автобусам малой вместимости с прицепом, чей вес превышает 750 кг.
Итак, категория «D» разрешает управлять автобусами.
Категория E
Водительское удостоверение с отметкой категория «Е» — подтверждает наличие права на управление составами транспортных средств с тягачом, относящимся к категориям «В», «С» или «D», которыми водитель имеет право управлять, но которые не входят сами в одну из этих категорий или в эти категории.
Но чтобы открыть категорию «Е», у вас должны быть открыта одна из категорий (или все) B,C,D. То есть категория «Е» идет как дополнение к основным категориям. При получении категории «Е» в графу «Особые отметки» проставляются следующие отметки: E-B, E-C, E-D, E-BC, E-BD, E-CD, E-BCD. В предыдущих категориях упоминалось о прицепе. Так вот, в зависимости от того, к какому транспортному средству будет подцеплен прицеп, соответственно будет проставлена отметка.
Категория E разрешает управлять транспортными средствами:
«E-B» — с прицепом, разрешенная максимальная масса которого по крайней мере 1000 кг, а разрешенная максимальная масса состава транспортных средств превышает 3500 кг.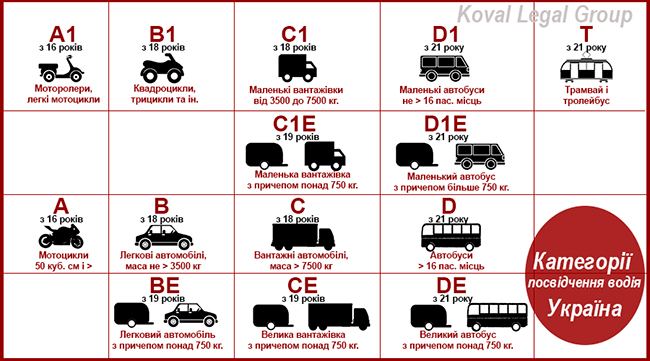
«E-C» — с полуприцепом или прицепом, имеющим не менее двух осей с расстоянием между ними более 1 м. «E-D» — на сочлененном автобусе.
Комбинации E-BC, E-BD, E-CD, E-BCD дают возможность управлять транспортными средствами из двух или трех подкатегорий.
Итак, категория «E» разрешает управлять транспортными средствами с прицепом.
Теперь мы знаем, на какие категории делятся транспортные средства и какие категории должны быть открыты в правах для конкретного вида транспорта. Но имейте в виду, что имя водительское удостоверение с одной категорией, например «C» (грузовики), вы не имеете право управлять легковыми автомобилями, для этого уже нужна категория «B».
В общем, чтобы управлять определенным видом транспорта, вам нужно открыть соответствующую категорию водительского удостоверения. Ну а если у вас в водительском удостоверении одна категория, а автомобиль, которым в управляете, относится к другой категории, то за это предусмотрен штраф!
На этом все, желаю вам успехов!
Содержание статьи:
- расшифровка категорий водительских прав
- водительские категории
- расшифровка водительского удостоверения
- тюфшЄхы№ёъшх ърЄхуюЁшш
Права Категории A, A1, A2, AM
A1 A2 A AM
19. 01.2013 в Германии были приняты новые положения в обучении и присвоении водительского удостоверения на категории А (мотоцикл) и В (легковой автомобиль).
01.2013 в Германии были приняты новые положения в обучении и присвоении водительского удостоверения на категории А (мотоцикл) и В (легковой автомобиль).
Обучение на мотоциклах проводится по категориям А1, А2 и А.
В программу обучения на категории А, А1 и А2 для начинающих водителей, не имеющих никакой категории, входят:
Обязательное посещение теоретического курса, состоящего из 12 общеобразовательных тем и 4 тем по категории А. Продолжительность каждого занятия 90 минут. Теоретический экзамен можно, по желанию, сдавать на русском языке.
Практическое обучение вождению на мотоцикле согласно установленному плану, включая обучение на автобане или скоростном шоссе, дорогах вне населенных пунктов и в темное время суток.
При наличии категории В (Klasse B) количество общеобразовательных тем по теории сокращается до 6, практическое обучение остается в полном объеме.
При переобучении одного из классов мотоцикла на другой также меняется объем теоретических занятий и практического вождения. (См. подробную информацию по интересующему Вас классу)
(См. подробную информацию по интересующему Вас классу)
Обучение проходит на новых современных мотоциклах, при желании на русском языке.
Klasse A – Категория А
Водительское удостоверение на категорию А выдается при условии, что обучающемуся исполнилось полных 24 года.
В качестве альтернативы возможны следующие варианты:
А1 (возраст 16 лет) –> А2 (возраст 18 лет) – > А (возраст 20 лет)
При переобучении через два года на возрастающую категорию требуется пересдать только лишь практический экзамен продолжительностью 40 минут.
Водителю, имеющему уже категорию А1 и желающему получить категорию А, должно исполниться полных 24 года. Для получения водительского удостоверения на класс А ему необходимо пройти теоретическое и практическое обучение в полном объеме и сдать оба экзамена.
При переобучении менее чем через два года на возрастающую категорию, например, с класса А1 на класс А2, или с класса А2 на класс А, или с класса А1 на класс А необходимо учитывать достигнутый возраст:
Имеющему водительское удостоверение на категорию А1 с переобучением менее чем через два года на категорию А2 должно быть полных 18 лет, с переобучением с категории А2 на категорию А должно быть полных 20 лет.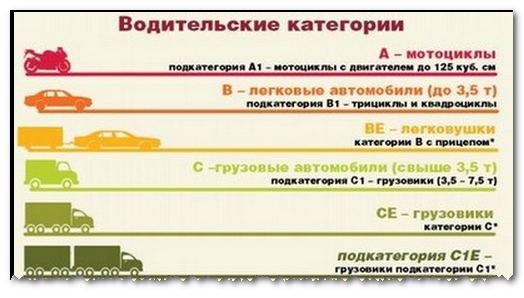
В данном случае обучающийся должен прослушать теоретический курс, состоящий из 6 тем по основам дорожного движения и 4 тем по управлению мотоциклом, и выполнить обязательные практические занятия на проселочных дорогах (3 х 45 минут), автобане ( 2 х 45 минут) и в темное время суток (1 х 45 минут). Во время обучения предписано сдать оба экзамена.
После завершения обучения на категорию А разрешается управлять следующими транспортными средствами:
мощностью более 15 киловатт
симметрично расположенными колесами
с объемом двигателя более 50 см3 и максимальной скоростью более 45 км/час
Klasse A1 – Категория А1
Обучение на категорию А1 разрешается начинать в возрасте 16 лет. Водительское удостоверение выдается без ограничения времени.
Имея права на категорию А1 разрешается управлять следующими транспортными средствами:
— «легкий» мотоцикл, также с коляской, объемом цилиндра до 125 см3 и мощностью двигателя не более 11 киловатт
— трехколесные мотоциклы ( Trikes ) с симметрично расположенными колесами и объемом двигателя более 50 см3 или мотоциклы с максимальной скоростью более 45 км/ час и мощностью двигателя до 15 киловатт.
В категорию А1 входит категория АМ. После завершения обучения на категорию А1 водительские права выдаются с испытательным сроком 2 года.
Программа обучения на категорию А1 для начинающих :
Теоретическое обучение
12 общеобразовательных тем и 4 темы по категории А
Практическое обучение
уроки вождения для подготовки к практическому экзамену и предписанные часы обучения на проселочных дорогах ( 5 х 45 минут), автобане или скоростном шоссе ( 4 х 45 минут) и в темное время суток ( 3 х 45 минут)
Klasse A2 – Категория А2
Обучение на категорию А2 разрешается начинать в возрасте 18 лет. Водительское удостоверение выдается без ограничения времени. Наличие прав на другие категории не обязательно.
При наличии категории А1 Вы можете через два года сдать практический экзамен и получить права на категорию А2.
Если Вы решили через два года получить водительское удостоверение на категорию А, то Вам следует сдать только практический экзамен (укороченный вариант: продолжительность экзамена – 40 минут) .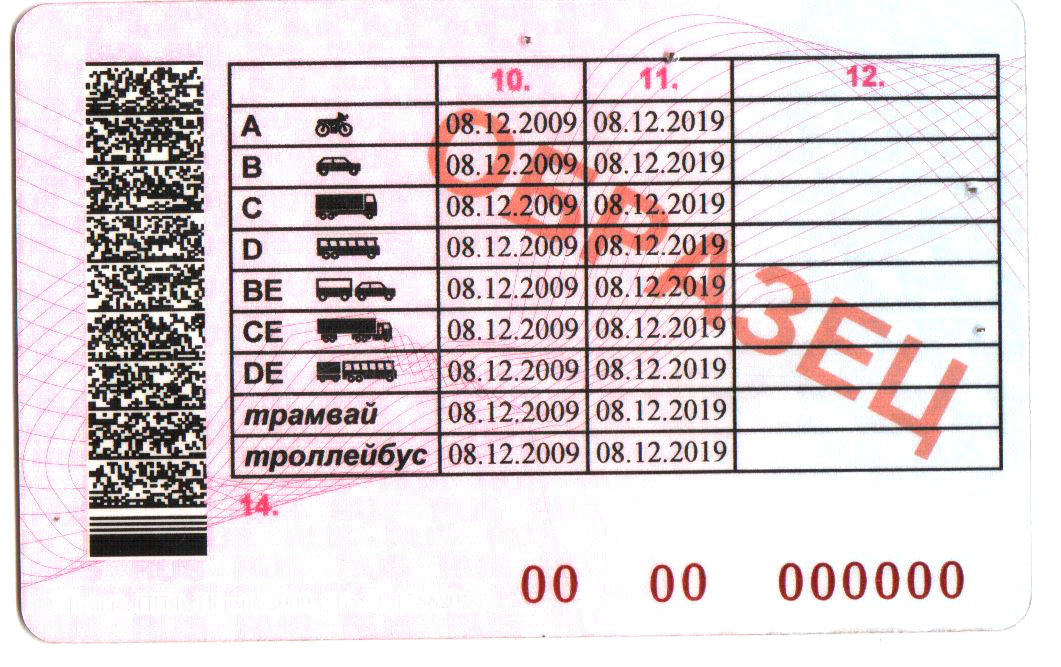
При таком поэтапном обучении ( категория А1 в 16 лет, категория А2 в 18 лет и категория А в 20 лет) в программу практического вождения не входят занятия на проселочных дорогах, автобанах и в темное время суток.
Имея данную категорию можно управлять мотоциклом – также и с коляской – мощностью не более 35 киловатт и отношением мощности двигателя к массе мотоцикла не более 0,2 Kw / kg.
Программа обучения на категорию А2 для начинающих :
Теоретическое обучение
12 общеобразовательных тем и 4 темы по категории А
Практическое обучение
уроки вождения для подготовки к практическому экзамену и предписанные часы обучения на проселочных дорогах ( 5 х 45 минут), автобане или скоростном шоссе ( 4 х 45 минут) и в темное время суток ( 3 х 45 минут)
Klasse AM – Категория АМ
Обучение на категорию АМ разрешается начинать в возрасте 16 лет.
В программу теоретического обучения входят 12 общеобразовательных тем по правилам дорожного движения и 2 темы по категории АМ.
В практическое обучение входят уроки вождения для развития навыков самостоятельного управления транспортным средством и подготовки к практическому экзамену.
После завершения обучения на категорию АМ разрешается управлять следующими траспортными средствами:
двухколесные транспортные средства (мопед)
трехколесные транпортные средства (Trikes)
четырехколесные транспортные средства
с максимальной скоростью от завода – изготовителя до 45 км/час
оснащенные электроприводом или ДВС с объемом двигателя не более 50 см3
мощностью до 4 киловатт для электромоторов
Категории водительских прав в Украине 2020 – виды удостоверений
Категории водительских прав в Украине теперь несколько запутаны. Какое разрешение требуется для управления тем или иным транспортом, сразу и не понять. Однако здесь есть определенная система, и мы сейчас научим вас ориентироваться в данном вопросе.
Выучить категории водительских прав в Украине на самом деле несложно, хотя казалось бы, не всегда это водителям и нужно. Однако учтите, что когда-то эта тема может коснуться каждого, кто управляет транспортным средством в нашей стране.
Более десяти категорий вместо прежних пяти появились в европейском и отечественном законодательстве в 2013 году.
Итак, все категории базируются на простой и понятной системе, принятой еще в международной Венской конвенции о дорожном движении от 1968 (ст. 41). Она предусматривает четыре группы транспортных средств:
А – мотоциклы и мотороллеры;
B – легковые автомобили и другие легкие автомобили на их базе;
C – грузовые автомобили;
D – автобусы.
Читайте также: Як навчитись водити вантажний автомобіль
Украинские водительские удостоверения дважды пополнялись новыми подкатегориями
Каждая категория в настоящее время имеет подкатегории. Та, что обозначенная цифрой 1 (А1, В1 и т. д.) означает право на управление так сказать облегченной начальной версией транспортных средств соответствующей категории. Подкатегория с индексом Е (ВЕ, С1Е и т.д.) дает право на буксировку тяжелого прицепа. Однако, давайте о категории прав в Украине подробнее.
д.) означает право на управление так сказать облегченной начальной версией транспортных средств соответствующей категории. Подкатегория с индексом Е (ВЕ, С1Е и т.д.) дает право на буксировку тяжелого прицепа. Однако, давайте о категории прав в Украине подробнее.
Кстати: как получить водительское удостоверение в Украине: пошаговая инструкция
Чем можно управлять
Имея права определенной категории, в Украине по состоянию на март 2018 года можно управлять:
А1 – мопедами, мотороллерами и другими двухколесными (трехколесными) транспортными средствами, которые имеют двигатель с рабочим объемом до 50 куб. см или электродвигатель мощностью до 4 кВт;
А – средствами, в том числе с боковым прицепом и другими двухколесными транспортными средствами, которые имеют двигатель с рабочим объемом 50 куб. см и больше или электродвигатель мощностью 4 кВт и более;
В1 – квадро- и трициклами, мотоколясками и другими трехколесными (четырехколесными) транспортными средствами, разрешенная максимальная масса которых не превышает 400 кг;
В – любыми автомобилями, пассажирскими и легкими грузовыми, разрешенная максимальная масса которых не превышает 3500 кг (7700 фунтов), а количество сидячих мест, помимо сиденья водителя, – восьми;
Читайте также: Как сделать автомобиль экономичнее
С1 – предназначенные для перевозки грузов автомобилями, разрешенная максимальная масса которых составляет от 3500 до 7500 кг (от 7700 до 16500 фунтов)
С – предназначенные для перевозки грузов автомобилями, разрешенная максимальная масса которых превышает 7500 кг (16500 фунтов)
D1 – предназначенными для перевозки пассажиров автобусами, в которых количество мест для сидения, кроме сидения водителя, не превышает 16;
D – предназначенными для перевозки пассажиров автобусами, в которых количество мест для сидения, кроме сидения водителя, более 16;
Т – трамваями и троллейбусами.
С категориями ВЕ, С1Е, СЕ, D1E, DE в правах можно управлять составами транспортных средств с тягачом в соответствии категории В, С1, С, D1 или D и с прицепом массой более 750 кг. Для управления автопоездом в составе прицепа меньшей массы подкатегория с индексом Е не нужна, достаточно иметь удостоверение на право управления автомобилем, который выступает в роли тягача.
Вместе с появлением новых подкатегорий прав в 2010-х годах появились новые условия их получения. Открыть новую категорию, даже более низкую относительно имеющейся, стало труднее.
Отметим, что для некоторых категорий прав установлены определенные ограничения по возрасту.
Водительское удостоверение в Украине могут получить лица, достигшие:
• 16 лет – категории А1, А;
• 18 лет – В1, В, С1, С;
• 19 лет – категории ВЕ, СЕ, С1Е;
• 21 года – категории D1, D, D1E, DE, T.
Вот такие категории прав действуют в Украине согласно Венской конвенции о дорожном движении от 1968 года и с позднейшими поправками, а также в соответствии с «Положением о порядке выдачи удостоверений водителя и допуска граждан к управлению транспортными средствами» Постановления Кабмина Украины № 340 и № 511.
Читайте также: Сколько можно выпить за рулем?
Бунт на Капитолии: расшифровка экстремистских символов, групп во время восстания на Капитолийском холме
Флаги, знаки и символы расистских, сторонников превосходства белой расы и экстремистских групп были показаны вместе с баннерами Трампа 2020 и американскими флагами во время беспорядков в среду у Капитолия США.Фотографии рассказывают часть истории убеждений некоторых из тех, кто решил явиться в тот день — от страстных и мирных сторонников Трампа до экстремистов, которые продемонстрировали свою ненависть с помощью своих символов, а также своими действиями.
СВЯЗАННЫЙ: Аресты Капитолия США: Список обвинений для арестованных в хаосе округа Колумбия
Смешивание групп — одна из проблем, которая давно беспокоит экспертов, отслеживающих экстремизм и ненависть.
Утверждение результатов выборов оказалось именно тем мероприятием, которое объединило различные группы и могло привести к распространению радикальных идей, говорят они. Первоначальное мероприятие, которое активно продвигалось и поддерживалось президентом Трампом, дало всем этим группам возможность сплотиться.
Первоначальное мероприятие, которое активно продвигалось и поддерживалось президентом Трампом, дало всем этим группам возможность сплотиться.
«Это мероприятие было направлено против результатов свободных и справедливых демократических выборов и естественной смены власти», — сказал Марк Питкэвидж, историк и эксперт по экстремизму из Антидиффамационной лиги.
Си-эн-эн поговорила с ним, чтобы определить символы и понять леденящие кровь послания тирании, превосходства белых, анархии, расизма, антисемитизма и ненависти, которые они изображают.
Петля и виселица
Хотя петля сама по себе часто используется как форма расового запугивания, Питкэвидж считает, что в этом контексте виселица должна была предполагать наказание за совершение государственной измены.«Это предполагает, что представители и сенаторы, которые голосуют за подтверждение результатов выборов, и, возможно, вице-президент Пенс, совершают измену и должны быть преданы суду и повешены», — поясняет он.
Эта риторика об измене была замечена на досках объявлений правых за несколько дней до этого события.
Флаг «Три процента»
«Три процента» (также известные как «третьи проценты», «3 процента» или «тройки») являются частью движения ополченцев в США и являются антиправительственными экстремистами, согласно ADL.
Как и другие участники движения ополченцев, «Три процента» считают себя защитниками американского народа от правительственной тирании.
«Поскольку многие сторонники ополчения решительно поддерживают президента Трампа, в последние годы« Трехпроцентники »не так активно выступали против федерального правительства, направляя свой гнев на других предполагаемых врагов, включая левых / антифа, мусульман и иммигрантов», согласно ADL.
Название группы происходит от неточного утверждения о том, что только три процента жителей колоний вооружились и воевали против британцев во время Войны за независимость.
Флаг, показанный выше, является их логотипом на традиционном флаге Бетси Росс. Питкэвидж говорит, что правые группы (мейнстримные или экстремистские), считающие себя патриотами, иногда кооптируют первый флаг Америки.
Питкэвидж говорит, что правые группы (мейнстримные или экстремистские), считающие себя патриотами, иногда кооптируют первый флаг Америки.
Флаг «Освободить Кракена»
Флаг ссылается на комментарии бывшего адвоката Трампа Сидни Пауэлла о том, что она собиралась «освободить Кракена». Пауэлл ложно заявила, что у нее есть доказательства, которые разрушили бы идею о том, что Джо Байден выиграл президентский пост.
«Кракен», гигантское морское существо из скандинавского фольклора, превратилось в мем в кругах, которые считают, что выборы были украдены.Они говорят, что Kraken — это кладезь доказательств широко распространенного мошенничества. В социальных сетях широко распространяются сообщения о заговоре QAnon и второстепенные сайты #ReleaseTheKraken наряду с ложными теориями мошенничества.
Гордые мальчики и знак ОК
Крайне правые использовали знак ОК как троллинговый жест, а для некоторых — как символ силы белых. ADL добавила этот символ в давнюю базу данных лозунгов и символов, используемых экстремистами.
«Они носят оранжевые кепки, чтобы идентифицировать друг друга; на прошлых митингах они носили опознавательные рубашки и другое снаряжение, но они отказались от этого для этого события после того, как их лидер был недавно арестован», — пояснил Питкэвидж.
The Proud Boys поддерживали президента Трампа и присутствовали на митингах «Stop The Steal» в Вашингтоне, округ Колумбия. Лидер The Proud Boys Генри Таррио, которого зовет Энрике Таррио, был освобожден из-под стражи во вторник по обвинениям, связанным с якобы сожжением баннера Black Lives Matter, взятого из черной церкви в прошлом месяце во время протестов в городе после акции «Stop the Steal» «митинг в прошлом месяце. Местный судья приказал ему держаться подальше от Вашингтона в ожидании суда, в том числе во время протестов на этой неделе.
Флаги «Кекистан»
Зелено-бело-черный флаг был создан некоторыми членами онлайн-сообщества 4chan, чтобы представить выдуманную страну-шутку, названную в честь «Кека», вымышленного бога, которого они также создали.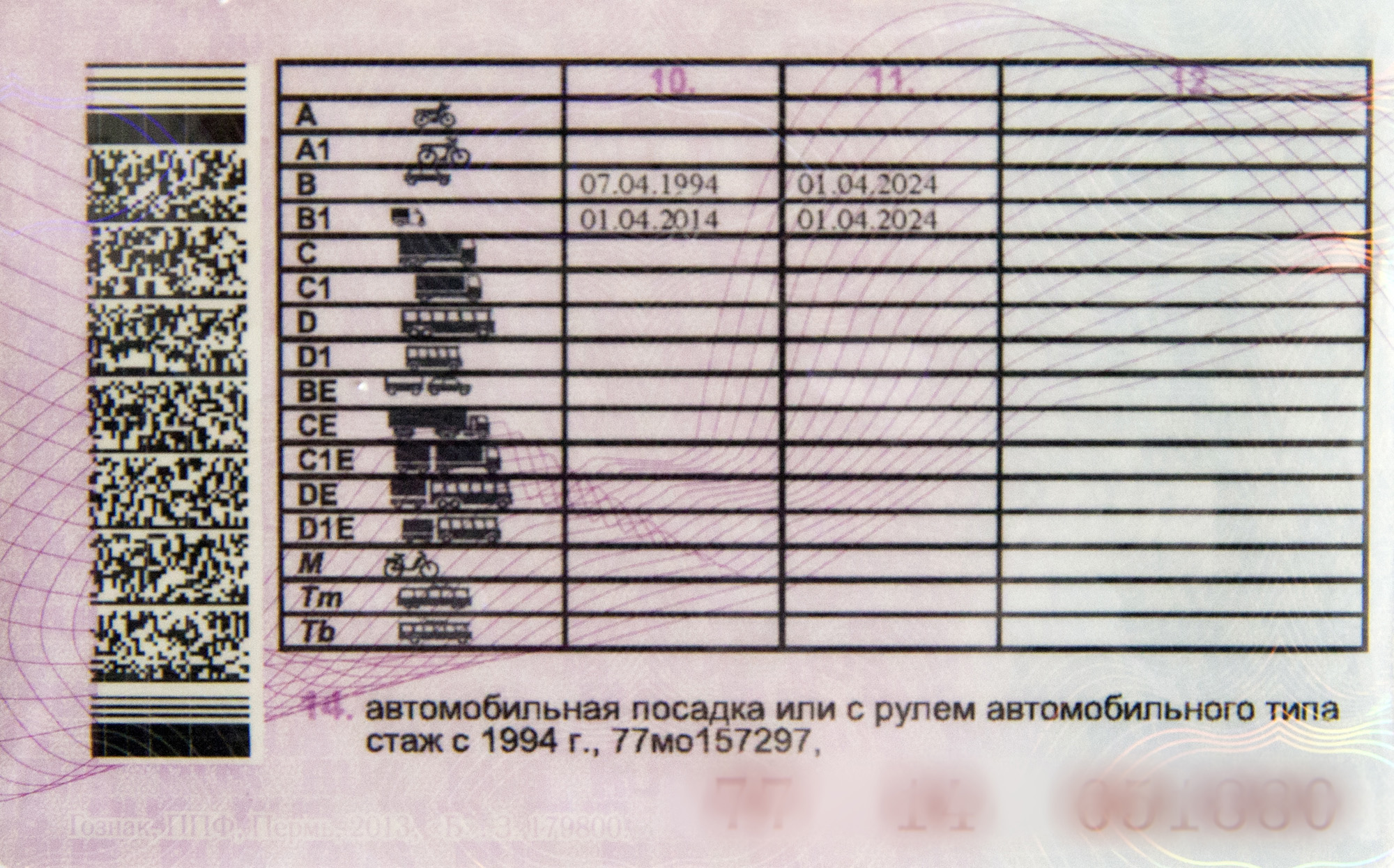 Давно присутствует на митингах правых и крайне правых.
Давно присутствует на митингах правых и крайне правых.
«Флаг Кекистана вызывает споры, потому что его дизайн частично заимствован из флага нацистской эпохи; это, по-видимому, было сделано специально в шутку», — пояснил Питкавадж. «Молодые правые, выходцы из субкультуры 4chan (как основные правые, так и крайне правые), часто любят вывешивать флаг Кекистана на митингах и мероприятиях.»
Измененные исторические флаги
Измененные флаги Конфедерации и Гадсдена были замечены в толпе у Капитолия. Одна из разновидностей боевого флага Конфедерации включала изображение штурмовой винтовки и слоган» Приходите и возьмите его «, чтобы передать анти-оружие Контрольное сообщение. Фраза «приди и возьми» перефразирует реплику «приди и возьми их», произнесенную спартанским царем Леонидом в битве при Фермопилах, когда персидский царь Ксеркс сказал ему и его людям сложить копья в обмен на свою жизнь. — сказал Питкавадж.
Флаг Гадсдена, известный многим как флаг «Не наступай на меня», является традиционным и историческим патриотическим флагом, датируемым американской революцией. Флаг и символ также популярны среди либертарианцев. Но это также было кооптировано правыми группами. Питкавадж объясняет, что, хотя некоторые используют его как символ патриотизма, другие используют его как «символ сопротивления предполагаемой тирании».
Флаг и символ также популярны среди либертарианцев. Но это также было кооптировано правыми группами. Питкавадж объясняет, что, хотя некоторые используют его как символ патриотизма, другие используют его как «символ сопротивления предполагаемой тирании».
Хранители присяги
В Капитолии виден мужчина в шляпе Хранителей присяги после того, как она была нарушена.Хранители присяги — это поддерживающая Трампа, крайне правая, антиправительственная группа, которая считает себя частью движения ополченцев, призванных защищать страну и защищать конституцию. Группа пытается вербовать членов из числа действующих или отставных военных, служб быстрого реагирования или полиции.
Их лидер извергал обширные теории заговора в своем блоге, обвинял демократов в краже результатов выборов, ранее угрожал насилием, если это будет необходимо в день выборов во время интервью с крайне правым заговорщиком Алексом Джонсом, и сказал, что его группа будет вооружена для защиты Белый дом при необходимости, сообщает ADL.
Флаг Конфедерации
Во время долгой Гражданской войны в Соединенных Штатах боевой флаг Конфедерации не появлялся в тени Капитолия США, но в среду мятежник пронес один прямо через его залы.
Фотографы запечатлели человека, несущего его мимо портретов аболициониста Чарльза Самнера и рабовладельца Джона Калхуна.
Флаг всегда был символом поддержки рабства. После Второй мировой войны он стал ярким символом Джима Кроу и сегрегации, неудивительно, по словам Питкэвэджа, это популярный символ среди сторонников превосходства белой расы — даже за пределами Соединенных Штатов.
Флаг Америки прежде всего
Мятежник облачается в флаг «Америка прежде всего» с логотипом подкаста крайне правого комментатора Ника Фуэнтеса. Фуэнтес присутствовал на мероприятии в Капитолии, но был сфотографирован, оставаясь за пределами здания Капитолия.
«Америка прежде всего» — также лозунг, который президент Трамп использовал при описании своей внешней политики. Его принятие подверглось критике со стороны ADL, заявившей, что оно использовалось в антисемитских целях, чтобы удержать США от участия во Второй мировой войне.
Его принятие подверглось критике со стороны ADL, заявившей, что оно использовалось в антисемитских целях, чтобы удержать США от участия во Второй мировой войне.
ADL утверждает, что Фуэнтес является частью «армии гройперов», которую ADL называет группой сторонников превосходства белых.
«В то время как взгляды группы и руководства совпадают с взглядами сторонников превосходства белой расы альт-правыми, гройперы пытаются нормализовать свою идеологию, присоединяясь к« христианству »и« традиционным »ценностям, якобы отстаиваемым церковью, включая брак и семью, «ADL объясняет. «Подобно альт-правым и другим сторонникам превосходства белых, гройперы считают, что они работают, чтобы защитить себя от демографических и культурных изменений, которые разрушают« истинную Америку »- белую христианскую нацию.«
» Лагерь Освенцим »
Мятежник внутри Капитолия был одет в толстовку« Лагерь Освенцим ». На нижней части рубашки написано« Работа приносит свободу », что является приблизительным переводом слов« Arbeitmacht frei »на воротах нацистский концлагерь. Освенцим был самым большим и самым печально известным нацистским концентрационным лагерем, в котором во время Второй мировой войны было убито около 1,1 миллиона человек.
Освенцим был самым большим и самым печально известным нацистским концентрационным лагерем, в котором во время Второй мировой войны было убито около 1,1 миллиона человек.
Питкавадж говорит, что, по его мнению, рубашка пришла с ныне несуществующего веб-сайта Aryanwear. Дизайн, имеющий существует уже около 10 лет, по данным Pitcavage, в последние недели появляется на разных веб-сайтах, хотя часто удаляется при подаче жалобы.
Наклейки Nationalist Social Club
На изображении в социальной сети видны наклейки Nationalist Social Club на том, что, кажется, является оборудованием полиции Капитолия США. Неясно, когда была сделана фотография, но она была опубликована в среду в чате Telegram, который использует группа, включая нацистский символ как часть их имени.
NSC, очевидно, игра слов о национал-социалистах или нацистской партии, является неонацистской группировкой, у которой есть региональные отделения как в Соединенных Штатах, так и по всему миру, согласно ADL. Неясно, относится ли наклейка справа к отделению в Новой Англии или потому, что группа изначально называла себя Клубом националистов Новой Англии.
Неясно, относится ли наклейка справа к отделению в Новой Англии или потому, что группа изначально называла себя Клубом националистов Новой Англии.
«Члены КНБ видят себя солдатами, ведущими войну с враждебной, контролируемой евреями системой, которая намеренно замышляет вымирание белой расы», согласно ADL. «Их цель — сформировать подпольную сеть белых людей, которые готовы сражаться со своими предполагаемыми врагами посредством локальных прямых действий».
MAGA Civil War 6 января 2021 г. рубашки
Остается много вопросов о том, как именно произошло нападение на Капитолий и кто возглавил атаку.Но призывы к свержению правительства и к гражданской или расовой войне уже давно вызывают крики в ультраправых кругах.
Рубашки, которые носили эти люди на территории Капитолия в среду, показывают, что, по крайней мере, было намерение отметить этот день. На них были футболки с заранее напечатанными рисунками, со ссылкой на подписанный Трамп лозунг «Сделаем Америку снова великой», а также слова «Гражданская война» и дата события, которое переросло в восстание.![]()
Многие комментаторы на ультраправых форумах писали после атаки, что это только начало той гражданской войны, которую многие из них давно желали.
(The-CNN-Wire и 2021 Cable News Network, Inc., компания Time Warner. Все права защищены.)
Страница не найдена
К сожалению, страница, которую вы искали на веб-сайте AAAI, не находится по адресу, который вы щелкнули или ввели:
https://www.aaai.org/papers/aaai/2008/aaai08-193.pdf Если указанный выше URL-адрес оканчивается на «.html», попробуйте заменить «.html:» на «.php» и посмотрите, решит ли это проблему.
Если вы ищете конкретную тему, попробуйте следующие ссылки или введите тему в поле поиска на этой странице:
- Выберите темы AI, чтобы узнать больше об искусственном интеллекте.
- Чтобы присоединиться или узнать больше о членстве в AAAI, выберите «Членство».
- Выберите Publications, чтобы узнать больше о AAAI Press и журналах AAAI.
- Для рефератов (а иногда и полного текста) технических документов по ИИ выберите Библиотека
- Выберите AI Magazine, чтобы узнать больше о флагманском издании AAAI.
- Чтобы узнать больше о конференциях и встречах AAAI, выберите Conferences
- Для ссылок на симпозиумы AAAI выберите «Симпозиумы».
- Для получения информации об организации AAAI, включая ее должностных лиц и сотрудников, выберите «Организация».

Помогите исправить страницу, которая вызывает проблему
Интернет-страница
, который направил вас сюда, должен быть обновлен, чтобы он больше не указывал на эту страницу. Вы поможете нам избавиться от старых ссылок? Пожалуйста, напишите веб-мастеру ссылающейся страницы или используйте его форму для сообщения о неработающих ссылках.Это может не помочь вам найти нужную страницу, но, по крайней мере, вы можете избавить других людей от неприятностей. Большинство поисковых систем и каталогов имеют простой способ сообщить о неработающих ссылках.
Если это кажется уместным, мы были бы признательны, если бы вы связались с веб-мастером AAAI, указав, как вы сюда попали (т. Е. URL-адрес страницы, которую вы искали, и URL-адрес ссылки, если таковой имеется). Спасибо!
Содержание сайта
К основным разделам этого сайта (и некоторым популярным страницам) можно перейти по ссылкам на этой странице.Если вы хотите узнать больше об искусственном интеллекте, вам следует посетить страницу AI Topics. Чтобы присоединиться или узнать больше о членстве в AAAI, выберите «Членство». Выберите «Публикации», чтобы узнать больше о AAAI Press, AI Magazine, и журналах AAAI. Чтобы получить доступ к цифровой библиотеке AAAI, содержащей более 10 000 технических статей по ИИ, выберите «Библиотека». Выберите Награды, чтобы узнать больше о программе наград и наград AAAI. Чтобы узнать больше о конференциях и встречах AAAI, выберите «Встречи». Для ссылок на программные документы, президентские обращения и внешние ресурсы ИИ выберите «Ресурсы».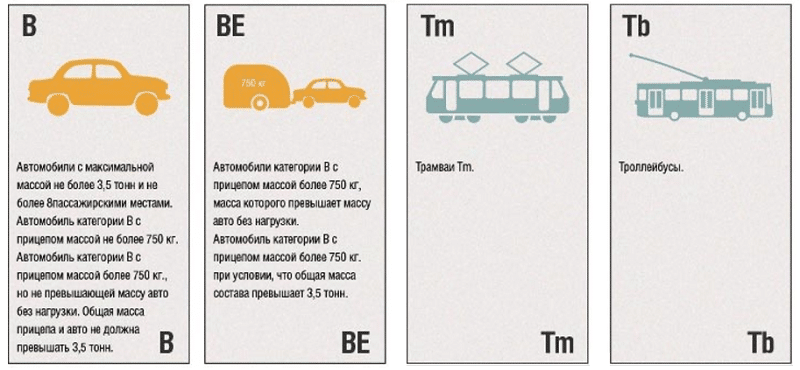 Для получения информации об организации AAAI, включая ее должностных лиц и сотрудников, выберите «О нас» (также «Организация»). Окно поиска, созданное Google, будет возвращать результаты, ограниченные сайтом AAAI.
Для получения информации об организации AAAI, включая ее должностных лиц и сотрудников, выберите «О нас» (также «Организация»). Окно поиска, созданное Google, будет возвращать результаты, ограниченные сайтом AAAI.
границ | Расшифровка семантического содержания фильмов с естественным движением по активности мозга человека
Введение
В последнее десятилетие появился значительный интерес к расшифровке стимулов или психических состояний по активности мозга, измеренной с помощью функциональной магнитно-резонансной томографии (фМРТ).Ранние результаты в этой области (Kay et al., 2008; Mitchell et al., 2008; Naselaris et al., 2009; Nishimoto et al., 2011) вызвали значительный интерес к перспективам футуристических неинвазивных интерфейсов мозг-компьютер. который может выполнять «чтение мозга». Эти исследования показали, что с помощью BOLD фМРТ можно получить значительно больше информации, чем многие считали ранее (Kay et al., 2008). Кроме того, одно недавнее исследование, проведенное в нашей лаборатории, показало, что с помощью фМРТ можно декодировать появление быстро меняющихся естественных фильмов (Nishimoto et al. , 2011), оспаривая распространенное мнение о том, что фМРТ подходит только для изучения медленных явлений. Здесь мы расширяем нашу предыдущую работу, расшифровывая, какие категории объектов и действий присутствуют в естественных фильмах.
, 2011), оспаривая распространенное мнение о том, что фМРТ подходит только для изучения медленных явлений. Здесь мы расширяем нашу предыдущую работу, расшифровывая, какие категории объектов и действий присутствуют в естественных фильмах.
Мозговое декодирование можно рассматривать как проблему поиска стимула, S , который, скорее всего, вызвал наблюдаемые жирные ответы, R , при распределении вероятностей P (S | R) . На сегодняшний день для решения этой проблемы использовались два общих подхода: байесовское декодирование и прямое декодирование.При байесовском декодировании строится явная модель P (R | S) , чтобы предсказать ответ на основе стимула. Затем для инвертирования условной вероятности используется правило Байеса: P (S | R) = P (R | S) P (S) / P (R). Этот подход использовался для декодирования внешнего вида и семантической категории статических природных изображений (Naselaris et al., 2009), визуального внешнего вида естественных фильмов (Nishimoto et al. , 2011) и семантической категории изолированных визуальных объектов. или слова (Mitchell et al., 2008). Однако байесовское декодирование требует построения априорного распределения по стимулам, P (S) , и это непрактично, когда пространство декодирования велико (например, при декодировании естественных сцен или фильмов). В некоторых случаях эту проблему можно решить, используя большой эмпирический априор (Naselaris et al., 2009; Nishimoto et al., 2011). Однако у нас нет возможности оценить эмпирическую априорность категорий, появляющихся в естественных фильмах. Это затрудняет применение структуры байесовского декодирования к этой проблеме.
, 2011) и семантической категории изолированных визуальных объектов. или слова (Mitchell et al., 2008). Однако байесовское декодирование требует построения априорного распределения по стимулам, P (S) , и это непрактично, когда пространство декодирования велико (например, при декодировании естественных сцен или фильмов). В некоторых случаях эту проблему можно решить, используя большой эмпирический априор (Naselaris et al., 2009; Nishimoto et al., 2011). Однако у нас нет возможности оценить эмпирическую априорность категорий, появляющихся в естественных фильмах. Это затрудняет применение структуры байесовского декодирования к этой проблеме.
Другой популярный подход к этой проблеме — прямое декодирование. В этом подходе создается явная модель P (S | R) , которая напрямую предсказывает стимул на основе ответа. Прямое декодирование использовалось для декодирования того, какая из двух визуальных категорий просматривается (Haxby et al., 2001; Carlson et al., 2003; Cox and Savoy, 2003), о какой из двух категорий снится субъект (Horikawa et al.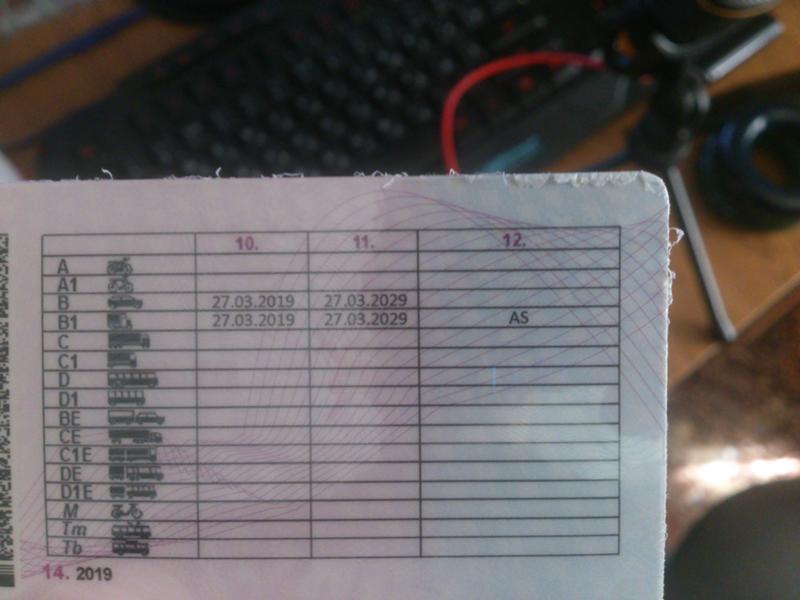 ., 2013), и какие объекты присутствуют в статических естественных визуальных сценах (Stansbury et al., 2013). Однако по нескольким причинам прямое декодирование обычно не является оптимальным для декодирования объектов и действий в естественных сценах мозговой активности. Во-первых, прямое декодирование неявно предполагает, что каждая декодируемая функция независима, но объекты и действия в естественных сценах обычно коррелируют друг с другом (хотя недавняя работа нашей лаборатории показала, что эту проблему можно обойти, преобразовав стимулы в пространство характеристик, в котором допущение независимости справедливо Stansbury et al., 2013). Во-вторых, каждый объект или действие имеет множество потенциальных ярлыков категорий, связанных во вложенной иерархической структуре. Например, 1993 Mercury Sable можно также назвать универсалом , автомобилем , автомобилем и т. Д. Эти метки не являются независимыми и поэтому не должны декодироваться независимо. Одним из решений этой проблемы было бы декодирование только одной метки в иерархии, например категории базового уровня (Rosch et al.
., 2013), и какие объекты присутствуют в статических естественных визуальных сценах (Stansbury et al., 2013). Однако по нескольким причинам прямое декодирование обычно не является оптимальным для декодирования объектов и действий в естественных сценах мозговой активности. Во-первых, прямое декодирование неявно предполагает, что каждая декодируемая функция независима, но объекты и действия в естественных сценах обычно коррелируют друг с другом (хотя недавняя работа нашей лаборатории показала, что эту проблему можно обойти, преобразовав стимулы в пространство характеристик, в котором допущение независимости справедливо Stansbury et al., 2013). Во-вторых, каждый объект или действие имеет множество потенциальных ярлыков категорий, связанных во вложенной иерархической структуре. Например, 1993 Mercury Sable можно также назвать универсалом , автомобилем , автомобилем и т. Д. Эти метки не являются независимыми и поэтому не должны декодироваться независимо. Одним из решений этой проблемы было бы декодирование только одной метки в иерархии, например категории базового уровня (Rosch et al. , 1976), которой в этом примере, вероятно, будет car .Однако декодер категории базового уровня будет игнорировать сигналы фМРТ, относящиеся к подчиненным категориям (например, универсал или 1993 Mercury Sable ), которые могут нести дополнительную информацию о визуальной сцене. Кроме того, получение меток категорий базового уровня потребует обширного ручного присвоения меток несколькими наблюдателями. По этим причинам мы решили использовать другой подход, в котором мы декодировали категории на многих разных уровнях иерархии одновременно.
, 1976), которой в этом примере, вероятно, будет car .Однако декодер категории базового уровня будет игнорировать сигналы фМРТ, относящиеся к подчиненным категориям (например, универсал или 1993 Mercury Sable ), которые могут нести дополнительную информацию о визуальной сцене. Кроме того, получение меток категорий базового уровня потребует обширного ручного присвоения меток несколькими наблюдателями. По этим причинам мы решили использовать другой подход, в котором мы декодировали категории на многих разных уровнях иерархии одновременно.
Наш подход прямого декодирования, иерархическая логистическая регрессия (HLR), декодирует, какие категории объектов и действий присутствуют в естественных фильмах, при этом фиксируя иерархические зависимости между ними. Логистическая регрессия — естественный выбор для моделирования системы с гауссовскими входами (например, жирным шрифтом) и двоичными выходами (такими как наличие или отсутствие определенной категории). Самый простой метод логистической регрессии — это построение отдельной модели для каждой категории.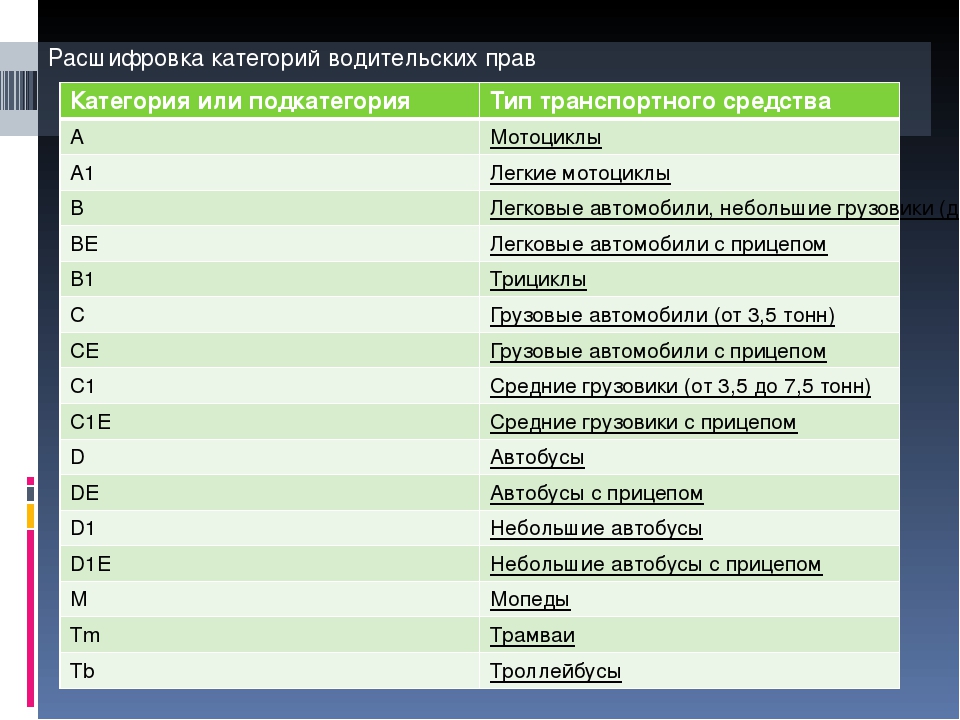 Однако этот подход неявно предполагает, что каждая категория независима от всех остальных.Это предположение явно неверно, когда категории связаны иерархически, и это может привести к бессмысленным результатам, таким как декодирование того, что сцена содержит автомобиль , но не автомобиль .
Однако этот подход неявно предполагает, что каждая категория независима от всех остальных.Это предположение явно неверно, когда категории связаны иерархически, и это может привести к бессмысленным результатам, таким как декодирование того, что сцена содержит автомобиль , но не автомобиль .
Мы решили эту проблему, объединив несколько моделей логистической регрессии вместе иерархически. Модель HLR декодирует условную вероятность того, что каждая категория присутствует, при условии, что присутствуют ее гиперонимы (ее вышестоящие или родительские категории в иерархии). Эти условные вероятностные отношения могут быть представлены в виде графической модели (рисунок 1).Графическая модель показывает, например, что совместная вероятность того, что сцена содержит категории автомобиль, автомобиль и универсал (с учетом вектора ответов мозга, R ), может быть разложена на произведение условных вероятности:
P (автомобиль, автомобиль, универсал | R) = P (автомобиль | R) × P (автомобиль | автомобиль, R) × P (универсал | автомобиль, R) Рисунок 1. Графическая модель иерархической логистической регрессии . Модель иерархической логистической регрессии (HLR) использовалась для фиксации зависимостей между декодируемыми категориями.Здесь показана часть графика WordNet. Белые узлы представляют категории для декодирования. Заштрихованный узел представляет наблюдаемые отклики вокселей. Модель HLR не декодирует каждую категорию из ответов независимо. Вместо этого он декодирует условную вероятность наличия гипонима (подчиненная или дочерняя категория), учитывая, что присутствуют его гиперонимы (вышестоящие или родительские категории). Затем декодированные вероятности гипонимов и гипонимов умножаются, чтобы вычислить вероятность наличия гипонима.
Графическая модель иерархической логистической регрессии . Модель иерархической логистической регрессии (HLR) использовалась для фиксации зависимостей между декодируемыми категориями.Здесь показана часть графика WordNet. Белые узлы представляют категории для декодирования. Заштрихованный узел представляет наблюдаемые отклики вокселей. Модель HLR не декодирует каждую категорию из ответов независимо. Вместо этого он декодирует условную вероятность наличия гипонима (подчиненная или дочерняя категория), учитывая, что присутствуют его гиперонимы (вышестоящие или родительские категории). Затем декодированные вероятности гипонимов и гипонимов умножаются, чтобы вычислить вероятность наличия гипонима.
Таким образом, совместная вероятность того, что сцена содержит автомобили категорий , автомобиль и универсал , равна произведению трех условных вероятностей (обратите внимание, что этот пример упрощен; в наших фактических данных автомобиль равен не категория высшего уровня). Кроме того, предельная вероятность того, что на сцене присутствует универсал категории , идентична этой совместной вероятности. Эта модель не рассматривает каждую категорию отдельно.Вместо этого предполагается, что каждая категория условно независима от других, учитывая ее гиперонимы. Эта структура обеспечивает разумное ограничение, согласно которому вероятность того, что автомобиль окажется на месте происшествия, никогда не превышает вероятность того, что на месте происшествия окажется автомобиль .
Кроме того, предельная вероятность того, что на сцене присутствует универсал категории , идентична этой совместной вероятности. Эта модель не рассматривает каждую категорию отдельно.Вместо этого предполагается, что каждая категория условно независима от других, учитывая ее гиперонимы. Эта структура обеспечивает разумное ограничение, согласно которому вероятность того, что автомобиль окажется на месте происшествия, никогда не превышает вероятность того, что на месте происшествия окажется автомобиль .
Чтобы оценить полную модель HLR, мы сначала оценили отдельную логистическую модель для каждой условной вероятности. Каждая логистическая модель предсказывает двоичное присутствие или отсутствие категории с учетом вектора воксельных ответов за несколько предыдущих временных точек, R .Условные вероятности моделировались путем ограничения набора данных, который использовался для оценки модели. Например, для оценки модели условной вероятности того, что автомобиль присутствует при условии, что присутствует автомобиль , мы использовали только моменты времени, когда присутствовал автомобиль (этот метод имеет побочное преимущество что делает оценку модели намного более эффективной, поскольку большинство условных моделей оцениваются с использованием небольших подмножеств полного набора данных).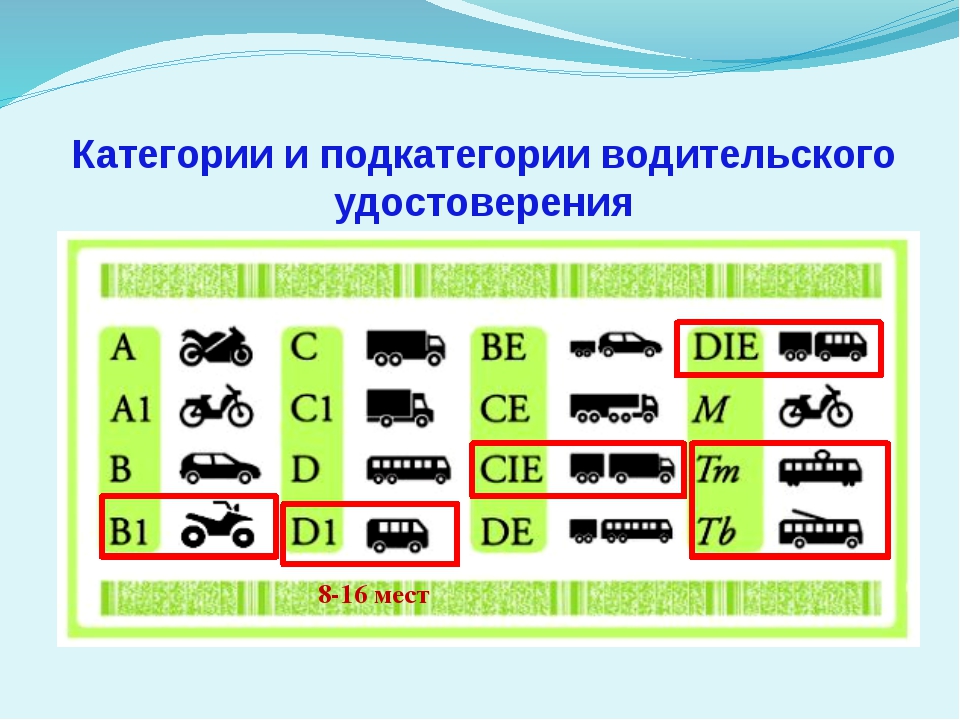 Логистические модели имеют отдельный вес для каждого из включенных вокселей в каждый момент времени. Чтобы учесть гемодинамическое отставание, также были включены ответы из нескольких временных точек (4, 6 и 8 с после декодирования стимула).
Логистические модели имеют отдельный вес для каждого из включенных вокселей в каждый момент времени. Чтобы учесть гемодинамическое отставание, также были включены ответы из нескольких временных точек (4, 6 и 8 с после декодирования стимула).
Чтобы определить наличие категории с помощью моделей HLR, мы умножили условные вероятности. Например, чтобы декодировать вероятность того, что автомобиль присутствовал в один момент времени, мы сначала извлекли соответствующие ответы вокселей, а затем использовали условную логистическую модель для оценки вероятности того, что автомобиль присутствовал, учитывая, что автомобиль присутствовал. , а затем использовали другую условную логистическую модель для оценки вероятности присутствия автомобиля .Наконец, мы умножили эти вероятности вместе, чтобы найти совместную вероятность того, что автомобиль и автомобиль присутствовали, учитывая ответы вокселей. Из этой формулировки ясно, что вероятность того, что присутствует автомобиль , никогда не может превышать совместную вероятность наличия автомобиля и автомобиля , таким образом, соблюдая иерархические отношения между этими категориями.
Мы применили структуру моделирования HLR к жирным ответам фМРТ, записанным от семи субъектов (рис. 2).Сначала были записаны ответы фМРТ, когда испытуемые смотрели 2 часа естественных фильмов. Семантическая таксономия WordNet (Miller, 1995) использовалась для обозначения основных категорий объектов и действий в каждом секундном сегменте фильмов. Используя 2 часа данных оценки модели, мы затем выбрали 5000 вокселей в коре головного мозга каждого субъекта, которые имели наиболее надежные ответы, связанные с категориями (подробности см. В разделе «Методы»). Метки категорий и ответы жирным шрифтом для 5000 выбранных вокселей были затем использованы для оценки отдельной модели HLR для каждого субъекта.Чтобы протестировать модели HLR, мы записали ЖЕЛТЫЕ ответы тех же испытуемых, пока они смотрели дополнительные 9 минут новых фильмов с естественными движениями, которые не использовались для оценки модели. Фильмы о проверке достоверности модели были повторены десять раз, и ответы были усреднены по повторам для уменьшения шума. Наконец, мы использовали модель HLR для каждого субъекта, чтобы расшифровать, какие категории присутствовали в проверочных фильмах.
Наконец, мы использовали модель HLR для каждого субъекта, чтобы расшифровать, какие категории присутствовали в проверочных фильмах.
Рисунок 2. Схема эксперимента . Эксперимент состоял из двух этапов: оценка модели и проверка модели .На этапе оценки модели семи испытуемым показали 2 часа естественных фильмов, в то время как ЖИРНЫЕ ответы были записаны с использованием фМРТ. Категории значимых объектов и действий были помечены в каждом сегменте продолжительностью 1 с. Затем были оценены модели прямого декодирования, которые оптимально предсказывали метки на основе линейных комбинаций воксельных ответов. На этапе проверки модели тем же семи испытуемым в течение 9 минут были показаны новые естественные киностимулы, которые не были включены в набор оценочных стимулов.Эти фильмы были повторены десять раз, и ответы были усреднены для уменьшения шума. Затем предварительно оцененные модели использовались для декодирования категорий, присутствующих в фильмах.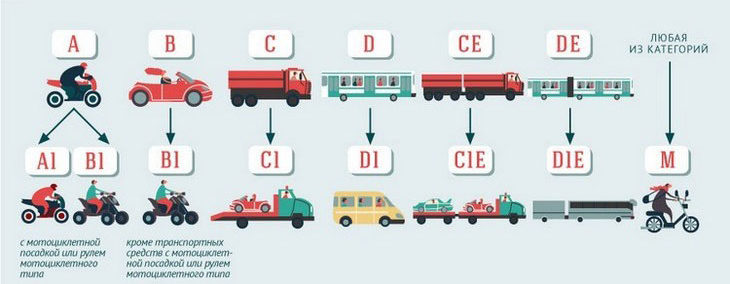 Для оценки производительности модели декодированные вероятности категорий сравнивались с фактическими метками категорий в отдельном наборе проверки, зарезервированном для этой цели.
Для оценки производительности модели декодированные вероятности категорий сравнивались с фактическими метками категорий в отдельном наборе проверки, зарезервированном для этой цели.
Материалы и методы
Субъекты
Функциональные данные были собраны у семи человек. Все субъекты не имели неврологических расстройств и имели нормальное или скорректированное зрение.Протокол эксперимента был одобрен Комитетом по защите человеческих субъектов Калифорнийского университета в Беркли. Письменное информированное согласие было получено от всех субъектов. Данные для пяти субъектов, использованных здесь, были такими же, как и данные, использованные в предыдущей публикации (Huth et al., 2012).
Экспериментальный образец
Стимулы для этого эксперимента состояли из 129 минут естественных фильмов, взятых из трейлеров к фильмам и других источников. Эти стимулы идентичны тем, которые использовались в более ранних экспериментах нашей лаборатории (Nishimoto et al. , 2011; Huth et al., 2012). WordNet использовался для обозначения заметных объектов и действий в каждом сегменте по 1 сек в этих фильмах (Huth et al., 2012). В результате получено 1364 уникальных метки. После добавления гиперинтативных меток общее количество категорий составило 1705.
, 2011; Huth et al., 2012). WordNet использовался для обозначения заметных объектов и действий в каждом сегменте по 1 сек в этих фильмах (Huth et al., 2012). В результате получено 1364 уникальных метки. После добавления гиперинтативных меток общее количество категорий составило 1705.
Сбор и предварительная обработка данных МРТ
Данные МРТ были собраны на сканере 3T Siemens TIM Trio в Центре визуализации мозга Калифорнийского университета в Беркли с использованием 32-канальной объемной катушки Siemens. Функциональные сканы были собраны с использованием последовательности градиентного эхо-EPI с временем повторения (TR) = 2.0045 с, время эха (TE) = 31 мс, угол переворота = 70 градусов, размер вокселя = 2,24 × 2,24 × 4,1 мм, размер матрицы = 100 × 100 и поле зрения = 224 × 224 мм. Вся кора головного мозга была взята с использованием 30–32 аксиальных срезов. Специально модифицированный биполярный радиочастотный (RF) импульс возбуждения воды использовался, чтобы избежать сигнала от жира.
Отдельные наборы данных оценки (соответствия) модели и проверки модели (тест) были собраны для каждого субъекта с чередованием в течение трех сеансов сканирования. Стимулы для набора данных оценки модели состояли из 120-минутных трейлеров к фильмам.Эти стимулы идентичны стимулам, использованным в Nishimoto et al. (2011) и Huth et al. (2012) и доступны для загрузки с CRCNS: https://crcns.org/data-sets/vc/vim-2/about-vim-2. Функциональные данные для набора данных оценки модели были собраны за 12 отдельных 10-минутных сканирований. Стимулы для набора данных проверки модели состояли из 9-минутных трейлеров к фильмам, повторенных 10 раз. Функциональные данные для набора данных проверки модели были собраны в 9 отдельных 10-минутных сканированиях, а затем усреднены. Обратите внимание, что стимулы оценки и проверки были полностью разными; в обоих наборах клипы не появлялись.На протяжении всей презентации стимулов для обоих наборов данных испытуемые зацикливались на точке, которая была наложена на фильм и расположена в центре экрана. Цвет точки менялся четыре раза в секунду для сохранения видимости.
Цвет точки менялся четыре раза в секунду для сохранения видимости.
В каждом прогоне корректировка движения проводилась с использованием инструмента регистрации линейных изображений FMRIB (FLIRT) из FSL 4.2 (Jenkinson and Smith, 2001). Затем был получен шаблонный объем высокого качества путем усреднения всех объемов в прогоне. FLIRT также использовался для автоматического согласования объема шаблона для каждого прогона с общим шаблоном, который был выбран в качестве шаблона для первого функционального прогона фильма по каждому предмету.Эти автоматические выравнивания проверялись вручную и корректировались на точность. Затем матрица перекрестного преобразования была объединена с матрицами преобразования коррекции движения, полученными с помощью MCFLIRT, и объединенное преобразование было использовано для повторной выборки исходных данных непосредственно в общее пространство шаблона.
Для каждого воксела смещение низкочастотного отклика вокселя определялось с помощью медианного фильтра с окном 120 с, и оно вычиталось из сигнала.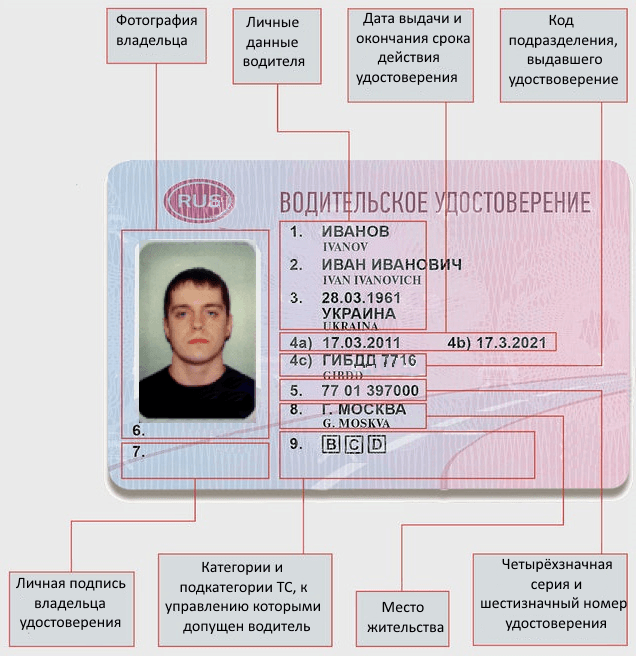 Затем вычитали средний отклик каждого воксела, а оставшийся отклик масштабировали до единичной дисперсии.
Затем вычитали средний отклик каждого воксела, а оставшийся отклик масштабировали до единичной дисперсии.
Анатомические изображения были получены с использованием импульсной последовательности T1 MP-RAGE. Затем эти изображения были сегментированы для получения трехмерного изображения кортикальной поверхности с использованием программного обеспечения Caret5 (Van Essen et al., 2001).
Оценка модели
Модель HLR включает отдельную модель условной логистической регрессии для каждой категории. Каждая модель условной логистической регрессии преобразует пространственно-временной паттерн активности вокселей в двоичное присутствие (1) или отсутствие (0) одной категории для временных точек, где присутствуют все гиперонимы этой категории.В то время как кора головного мозга содержит десятки тысяч вокселей, многие воксели очень шумны или содержат мало информации о стимулах. Таким образом, чтобы уменьшить сложность модели и уменьшить шум, только 5000 вокселей для каждого объекта были использованы в качестве входных данных для модели HLR. (Модели были протестированы на одном субъекте с использованием 1000, 5000 и 10000 вокселей. Наилучшая производительность была обнаружена при 5000 вокселей.) Чтобы найти лучшие 5000 вокселей для каждого объекта, мы сначала использовали регуляризованную линейную регрессию для оценки независимой модели кодирования для каждого воксель (модели кодирования предсказывают реакцию отдельных вокселей как взвешенную сумму по меткам двоичных категорий).Эта процедура моделирования повторялась 50 раз, каждый раз удерживая и прогнозируя ответы на отдельном сегменте набора данных оценки модели. Затем характеристики прогнозирования модели были усреднены по 50-кратным значениям и были отобраны 5000 лучших вокселей. Для этой процедуры использовался набор данных оценки модели, данные проверки были зарезервированы для использования в других местах.
(Модели были протестированы на одном субъекте с использованием 1000, 5000 и 10000 вокселей. Наилучшая производительность была обнаружена при 5000 вокселей.) Чтобы найти лучшие 5000 вокселей для каждого объекта, мы сначала использовали регуляризованную линейную регрессию для оценки независимой модели кодирования для каждого воксель (модели кодирования предсказывают реакцию отдельных вокселей как взвешенную сумму по меткам двоичных категорий).Эта процедура моделирования повторялась 50 раз, каждый раз удерживая и прогнозируя ответы на отдельном сегменте набора данных оценки модели. Затем характеристики прогнозирования модели были усреднены по 50-кратным значениям и были отобраны 5000 лучших вокселей. Для этой процедуры использовался набор данных оценки модели, данные проверки были зарезервированы для использования в других местах.
Для каждой сцены пространственно-временными входными данными для модели HLR является вектор длиной 15000, состоящий из ЖИРНЫХ ответов для 5000 выбранных вокселей в трех последовательных временных точках. Было включено несколько временных точек, потому что ЖИРНЫЕ ответы медленные, для подъема и спада требуется 5–15 с после нервного события (Boynton et al., 1996). Включение нескольких моментов времени в модель позволяет процедуре регрессии изучить линейный фильтр, который будет деконволюционировать медленную ЖИРНУЮ функцию отклика из временного хода стимула. Таким образом, чтобы предсказать наличие категории в момент времени t , модель использует воксельные ответы в моменты времени t + 2, t + 3 и t + 4 TR.При TR 2 с эти задержки соответствуют 4, 6 и 8 с.
Было включено несколько временных точек, потому что ЖИРНЫЕ ответы медленные, для подъема и спада требуется 5–15 с после нервного события (Boynton et al., 1996). Включение нескольких моментов времени в модель позволяет процедуре регрессии изучить линейный фильтр, который будет деконволюционировать медленную ЖИРНУЮ функцию отклика из временного хода стимула. Таким образом, чтобы предсказать наличие категории в момент времени t , модель использует воксельные ответы в моменты времени t + 2, t + 3 и t + 4 TR.При TR 2 с эти задержки соответствуют 4, 6 и 8 с.
Для построения каждой модели условной логистической регрессии мы использовали только подмножество данных оценки модели, в котором присутствовали все гиперонимы выбранной категории. Например, для построения модели для категории спортивный автомобиль мы выбрали все временные точки, в которых присутствовал автомобиль . Затем модель была оценена с использованием градиентного спуска с ранней остановкой. Сначала данные были разбиты на два набора: 90% данных использовались для градиентного спуска, а 10% — для оценки точки остановки.На каждой итерации веса обновлялись на основе данных градиентного спуска, а затем ошибка модели оценивалась с использованием данных ранней остановки. Если ошибка данных ранней остановки не уменьшалась в течение десяти последовательных итераций, процедура градиентного спуска прекращалась. Веса вокселей были инициализированы равными нулю, а параметр смещения был установлен для получения априорной вероятности категории с учетом ее гиперонима (априорная вероятность была вычислена эмпирически для всего обучающего набора данных). Каждая модель оценивалась трижды с использованием отдельных наборов данных для ранней остановки, а затем полученные веса были усреднены.
Сначала данные были разбиты на два набора: 90% данных использовались для градиентного спуска, а 10% — для оценки точки остановки.На каждой итерации веса обновлялись на основе данных градиентного спуска, а затем ошибка модели оценивалась с использованием данных ранней остановки. Если ошибка данных ранней остановки не уменьшалась в течение десяти последовательных итераций, процедура градиентного спуска прекращалась. Веса вокселей были инициализированы равными нулю, а параметр смещения был установлен для получения априорной вероятности категории с учетом ее гиперонима (априорная вероятность была вычислена эмпирически для всего обучающего набора данных). Каждая модель оценивалась трижды с использованием отдельных наборов данных для ранней остановки, а затем полученные веса были усреднены.
Мы проверили, дает ли этот градиентный спуск с ранней остановкой результаты, отличные от более стандартной регрессии с L2-штрафом, но обнаружили очень небольшую разницу. Мы реализовали регуляризованную логистическую регрессию L2 с помощью scikit-learn (Pedregosa et al. , 2011) с коэффициентами регуляризации от 10 −6 до 10 4 . Для каждого из трех бутстрапов мы подобрали модель для 90% данных и оценили потери на 10%, чтобы выбрать лучший коэффициент регуляризации.Затем мы взяли средний коэффициент регуляризации, найденный по бутстрапам, и использовали его для корректировки модели на всем обучающем наборе. Мы сравнили результаты этой процедуры с результатами, использующими подход раннего прекращения, и обнаружили, что в среднем регрессия с ранним прекращением работала немного лучше. Для всех категорий с AUC> 0,5 для любого метода регрессии AUC ранней остановки были в среднем выше на 0,09, и 59,0% категорий лучше декодировались моделью ранней остановки, чем регуляризацией L2.Эти различия, по-видимому, связаны с тем, что ранняя остановка намного лучше справляется с категориями с небольшим количеством положительных примеров.
, 2011) с коэффициентами регуляризации от 10 −6 до 10 4 . Для каждого из трех бутстрапов мы подобрали модель для 90% данных и оценили потери на 10%, чтобы выбрать лучший коэффициент регуляризации.Затем мы взяли средний коэффициент регуляризации, найденный по бутстрапам, и использовали его для корректировки модели на всем обучающем наборе. Мы сравнили результаты этой процедуры с результатами, использующими подход раннего прекращения, и обнаружили, что в среднем регрессия с ранним прекращением работала немного лучше. Для всех категорий с AUC> 0,5 для любого метода регрессии AUC ранней остановки были в среднем выше на 0,09, и 59,0% категорий лучше декодировались моделью ранней остановки, чем регуляризацией L2.Эти различия, по-видимому, связаны с тем, что ранняя остановка намного лучше справляется с категориями с небольшим количеством положительных примеров.
Чтобы избежать переобучения, выходные данные модели были сглажены до исходной априорной вероятности. Мы предположили, что бета-версия распределена по выходным данным модели, со средним значением, равным условной априорной вероятности для каждой категории. Затем мы подбираем параметр масштабирования η так, чтобы P * (Si | S \ i, R) = P (Si | S \ i, R) + ηPi, 01 + η максимизировали логарифмическую вероятность 1 мин удерживаемых данных (где P ( S i | S \ i , R ) — это результат логистической модели для этикетки i th с учетом меток других категорий и ответов, и P i , 0 — это априорная вероятность увидеть i -ю метку при наличии ее гиперонимов).Эта сглаженная вероятность использовалась во всех последующих анализах.
Мы предположили, что бета-версия распределена по выходным данным модели, со средним значением, равным условной априорной вероятности для каждой категории. Затем мы подбираем параметр масштабирования η так, чтобы P * (Si | S \ i, R) = P (Si | S \ i, R) + ηPi, 01 + η максимизировали логарифмическую вероятность 1 мин удерживаемых данных (где P ( S i | S \ i , R ) — это результат логистической модели для этикетки i th с учетом меток других категорий и ответов, и P i , 0 — это априорная вероятность увидеть i -ю метку при наличии ее гиперонимов).Эта сглаженная вероятность использовалась во всех последующих анализах.
Затем все модели отдельных категорий были объединены, чтобы сформировать модель HLR, которая описывает полное распределение вероятностей по всем меткам сцены.
Оценка моделис шумом на этикетке
Одна потенциальная проблема с описанным выше подходом логистической регрессии заключается в том, что присвоенные вручную метки категорий в наборе данных оценки модели могут быть неточными или зашумленными.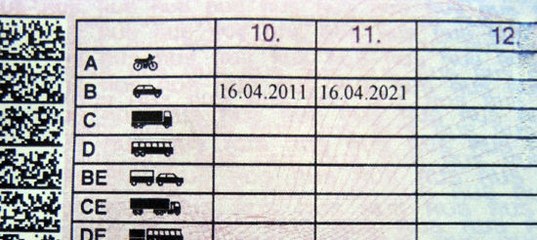 Чтобы учесть эту возможность, мы повторно оценили модели логистической регрессии для одного субъекта, используя метод из (Bootkrajang and Kabán, 2012), который итеративно оценивает матрицу вероятности переворота метки 2 × 2 для каждой категории, где первая строка представляет собой вероятность получение метки 0 или 1 при условии, что истинная метка равна 0, а вторая строка — это вероятность получения 0 или 1 при условии, что истинная метка равна 1.Мы дважды переоценили каждую модель логистической регрессии: сначала инициализировали все веса модели до нуля, а затем инициализировали веса модели значениями, найденными с использованием нашего более раннего подхода логистической регрессии. В обоих случаях мы инициализировали вероятность ошибки метки (то есть недиагональные значения в матрице переворачивания метки) равной 0,1. Для обоих условий матрица переворачивания быстро сходилась к единичной матрице почти в каждой категории. Максимальная предполагаемая вероятность ошибки метки равнялась 0. 0086 (т.е. менее 1%). Это говорит о том, что матрицы переворачивания меток для этого эксперимента практически неотличимы от единичной матрицы. Вероятно, это связано с тем, что наши стимулы были помечены вручную одним человеком, а не с использованием подхода краудсорсинга, такого как Механический турок Amazon.
Чтобы учесть эту возможность, мы повторно оценили модели логистической регрессии для одного субъекта, используя метод из (Bootkrajang and Kabán, 2012), который итеративно оценивает матрицу вероятности переворота метки 2 × 2 для каждой категории, где первая строка представляет собой вероятность получение метки 0 или 1 при условии, что истинная метка равна 0, а вторая строка — это вероятность получения 0 или 1 при условии, что истинная метка равна 1.Мы дважды переоценили каждую модель логистической регрессии: сначала инициализировали все веса модели до нуля, а затем инициализировали веса модели значениями, найденными с использованием нашего более раннего подхода логистической регрессии. В обоих случаях мы инициализировали вероятность ошибки метки (то есть недиагональные значения в матрице переворачивания метки) равной 0,1. Для обоих условий матрица переворачивания быстро сходилась к единичной матрице почти в каждой категории. Максимальная предполагаемая вероятность ошибки метки равнялась 0. 0086 (т.е. менее 1%). Это говорит о том, что матрицы переворачивания меток для этого эксперимента практически неотличимы от единичной матрицы. Вероятно, это связано с тем, что наши стимулы были помечены вручную одним человеком, а не с использованием подхода краудсорсинга, такого как Механический турок Amazon.
Оценка модели
Анализ рабочих характеристик приемника (ROC)
Для каждого момента времени в наборе данных проверки мы спрогнозировали вероятность того, что каждая категория присутствовала в стимуле, используя HLR.Затем ROC-анализ был использован для оценки производительности декодирования модели для каждой категории. Для проведения ROC-анализа мы постепенно увеличивали порог обнаружения с нуля до единицы. Для каждого порога мы вычислили количество ложноположительных обнаружений (точки, где прогнозируемый временной ход выше порогового значения, но категория отсутствует) и истинно положительных обнаружений (когда прогнозируемый временной ход выше порогового значения, а категория фактически равна присутствует в стимуле). Затем мы построили график истинно положительной скорости (TPR) против ложноположительной скорости (FPR) для всех пороговых значений, создав кривую ROC.
Затем мы построили график истинно положительной скорости (TPR) против ложноположительной скорости (FPR) для всех пороговых значений, создав кривую ROC.
Обычной статистикой, используемой для измерения эффективности обнаружения, является площадь под кривой ROC (AUC). Значение AUC, равное 1,0, представляет собой идеальное декодирование, где вероятность декодирования для любого момента времени, в котором категория фактически присутствует, выше, чем вероятность декодирования для каждого момента времени, в котором категория отсутствует. Мы определили уровень вероятности AUC, перетасовывая фактические двоичные метки для каждой категории во времени. Блоки из четырех ТУ перетасовывались 1000 раз, чтобы получить новые временные курсы с той же априорной вероятностью и автокорреляционной структурой, аналогичной исходным данным (мы протестировали блоки других размеров, но не обнаружили разницы в результатах).Затем вычислялась AUC для каждого из 1000 перетасованных курсов времени, и нулевое распределение AUC соответствовало бета-распределению с центром на 0,5. Наконец, мы вычислили вероятность получения фактического AUC при этом распределении. Фактическая AUC была объявлена значимой, если ее вероятность при этом нулевом распределении была ниже порога значимости. Пороги значимости были определены путем применения процедуры Бенджамини-Хохберга (Benjamini and Hochberg, 1995), чтобы ограничить частоту ложных открытий, q (FDR) , при множественных сравнениях до 0.01.
Наконец, мы вычислили вероятность получения фактического AUC при этом распределении. Фактическая AUC была объявлена значимой, если ее вероятность при этом нулевом распределении была ниже порога значимости. Пороги значимости были определены путем применения процедуры Бенджамини-Хохберга (Benjamini and Hochberg, 1995), чтобы ограничить частоту ложных открытий, q (FDR) , при множественных сравнениях до 0.01.
Вероятность модели
Анализ ROC проверяет, насколько хорошо каждая категория декодируется за все время. Однако также важно проверить, насколько хорошо все категории декодируются в каждый момент времени. Чтобы проверить это, мы рассчитали вероятность фактических меток категорий в каждый момент времени с учетом декодированных вероятностей категорий. Эта вероятность была вычислена как произведение вероятностей получения фактической двоичной метки для каждой категории в рамках модели. Для нулевой модели мы использовали априорную вероятность согласно набору данных оценки модели, которая была постоянной во времени. Затем мы количественно оценили производительность модели как отношение относительного логарифмического правдоподобия между моделью HLR и нулевой моделью. Чтобы оценить уровень вероятности, мы перетасовали выходные данные модели для каждой категории по времени 100000 раз, повторно вычисляя логарифмическое отношение правдоподобия при каждой перетасовке. Относительное логарифмическое правдоподобие было объявлено значимым, если вероятность согласно перемешанному распределению была ниже порога значимости ( p < 0,01 ).
Затем мы количественно оценили производительность модели как отношение относительного логарифмического правдоподобия между моделью HLR и нулевой моделью. Чтобы оценить уровень вероятности, мы перетасовали выходные данные модели для каждой категории по времени 100000 раз, повторно вычисляя логарифмическое отношение правдоподобия при каждой перетасовке. Относительное логарифмическое правдоподобие было объявлено значимым, если вероятность согласно перемешанному распределению была ниже порога значимости ( p < 0,01 ).
Результаты
Характеристики декодирования для отдельных категорий
На рис. 3 показана производительность декодирования модели HLR для одного субъекта для нескольких различных категорий: разговор, животное, транспортное средство и вещь (аналогичные графики для других шести субъектов показаны на дополнительных рисунках 1–7).Панели в левой части рисунка показывают временной ход декодированной категории в наборе данных проверки модели. Заштрихованные области указывают периоды, когда категория действительно присутствовала. Панели в правой части рисунка показывают кривую рабочей характеристики приемника (ROC) для декодера соответствующей категории. Заштрихованная область под кривыми ROC показывает плотность нулевого распределения кривых ROC, которая была определена перетасовкой. Все AUC, показанные на этом рисунке, значительно больше, чем ожидалось случайно (q (FDR) <0.01).
Заштрихованные области указывают периоды, когда категория действительно присутствовала. Панели в правой части рисунка показывают кривую рабочей характеристики приемника (ROC) для декодера соответствующей категории. Заштрихованная область под кривыми ROC показывает плотность нулевого распределения кривых ROC, которая была определена перетасовкой. Все AUC, показанные на этом рисунке, значительно больше, чем ожидалось случайно (q (FDR) <0.01).
Рис. 3. Временные курсы декодирования и характеристики декодирования одного предмета для четырех отдельных категорий . Результаты для четырех из 479 категорий, расшифрованных в этом исследовании. ( Left ) Каждая строка дает декодированную вероятность того, что определенная категория объекта или действия присутствовала в фильме с течением времени. Синие линии показывают вероятность декодирования, а серые области показывают моменты времени, когда категория действительно присутствовала в фильме. Декодированные вероятности для глагола говорить и существительного животное высоки, когда присутствуют эти категории, и ниже в другое время. Однако вероятности не точны по времени. Например, на 2,7 мин после начала фильма разговор появляется на один момент времени, но декодированная вероятность требует нескольких моментов времени для роста и падения. Декодированные вероятности существительного транспортное средство и существительного вещь (в частности, thing.n.12 , который включает такие разные категории, как водоем и часть тела ) менее точны, чем talk или животное .Однако модель декодирования правильно присваивает своим предсказаниям низкую достоверность, о чем свидетельствует тот факт, что вероятность декодирования для вещь колеблется около предшествующего значения 0,32. ( Справа ) Анализ рабочих характеристик приемника (ROC), обобщающий общую точность декодирования для каждой из четырех категорий. ROC строит график истинных положительных результатов (TPR) как функцию ложных положительных результатов (FPR) декодера. Производительность декодера показана синим цветом.
Однако вероятности не точны по времени. Например, на 2,7 мин после начала фильма разговор появляется на один момент времени, но декодированная вероятность требует нескольких моментов времени для роста и падения. Декодированные вероятности существительного транспортное средство и существительного вещь (в частности, thing.n.12 , который включает такие разные категории, как водоем и часть тела ) менее точны, чем talk или животное .Однако модель декодирования правильно присваивает своим предсказаниям низкую достоверность, о чем свидетельствует тот факт, что вероятность декодирования для вещь колеблется около предшествующего значения 0,32. ( Справа ) Анализ рабочих характеристик приемника (ROC), обобщающий общую точность декодирования для каждой из четырех категорий. ROC строит график истинных положительных результатов (TPR) как функцию ложных положительных результатов (FPR) декодера. Производительность декодера показана синим цветом. Эффективность вероятности определялась путем перетасовки временной шкалы стимула и пересчета кривой ROC (см. Методы).Распределение кривых на 1000 перетасовок показано на том же графике серым цветом. Площадь под кривой ROC (AUC) показана на каждой панели, а значимые значения (q (FDR) <0,01) отмечены звездочкой. Кривые ROC показывают, что как talk , так и animal декодируются точно, но vehicle и thing декодируются не особенно хорошо. Аналогичные графики для других шести субъектов показаны на дополнительных рисунках 1–7.
Эффективность вероятности определялась путем перетасовки временной шкалы стимула и пересчета кривой ROC (см. Методы).Распределение кривых на 1000 перетасовок показано на том же графике серым цветом. Площадь под кривой ROC (AUC) показана на каждой панели, а значимые значения (q (FDR) <0,01) отмечены звездочкой. Кривые ROC показывают, что как talk , так и animal декодируются точно, но vehicle и thing декодируются не особенно хорошо. Аналогичные графики для других шести субъектов показаны на дополнительных рисунках 1–7.
В первой строке рисунка 3 показан временной график для глагола talk .Вероятности декодирования очень высоки, когда в фильме присутствует разговор , , и относительно низки в другое время. В декодированной временной шкале нет ложноположительных пиков. Однако декодированный временной ход не является точным во времени: для подъема и спада требуется несколько секунд. Например, на 2,7 мин после начала фильма разговор появляется на один момент времени, но вероятность декодирования начинает расти на несколько временных точек раньше, а затем требуется несколько временных точек, чтобы вернуться к базовому уровню после исчезновения категории. Эта временная неточность проявляется даже в том случае, если модель HLR включает ответы на множественные временные задержки, которые должны частично компенсировать вялую гемодинамическую реакцию. Это может быть связано с тем, что модель HLR декодирует категории в каждый момент времени независимо и не учитывает категории, декодированные для других моментов времени. Тем не менее, площадь под кривой ROC (AUC) составляет 0,918, демонстрируя, что декодер чрезвычайно точен. Это говорит о том, что кортикальное представление talk достаточно устойчиво, чтобы его можно было надежно декодировать с помощью фМРТ.
Эта временная неточность проявляется даже в том случае, если модель HLR включает ответы на множественные временные задержки, которые должны частично компенсировать вялую гемодинамическую реакцию. Это может быть связано с тем, что модель HLR декодирует категории в каждый момент времени независимо и не учитывает категории, декодированные для других моментов времени. Тем не менее, площадь под кривой ROC (AUC) составляет 0,918, демонстрируя, что декодер чрезвычайно точен. Это говорит о том, что кортикальное представление talk достаточно устойчиво, чтобы его можно было надежно декодировать с помощью фМРТ.
Во второй строке рисунка 3 показан расшифрованный временной график для категории животных . AUC для животных составляет 0,911, что снова указывает на чрезвычайно высокую точность декодера. Как и в случае с talk , это предполагает, что кортикальное представление животного является достаточно устойчивым, чтобы его можно было надежно декодировать с помощью фМРТ.
Третья строка на Рисунке 3 показывает декодированный временной ход для категории транспортного средства (это общая категория, которая включает несколько более конкретных категорий, таких как автомобиль , мотоцикл и лодка ).Декодированный временной ход очень высок и составляет 6,1 мин, когда транспортное средство фактически присутствует в стимуле. Однако декодированный временной ход был низким в течение нескольких других периодов, когда присутствовало транспортное средство . В другое время, например 0,5 мин, декодированный временной график высокий, но транспортное средство отсутствует. В этом случае AUC составляет 0,758, что указывает на удовлетворительную точность декодера. Это предполагает, что кортикальное представление транспортного средства не так надежно или отличительно, как представления talk или животного .
Четвертая строка на Рисунке 3 показывает декодированный временной ход для вещи категории .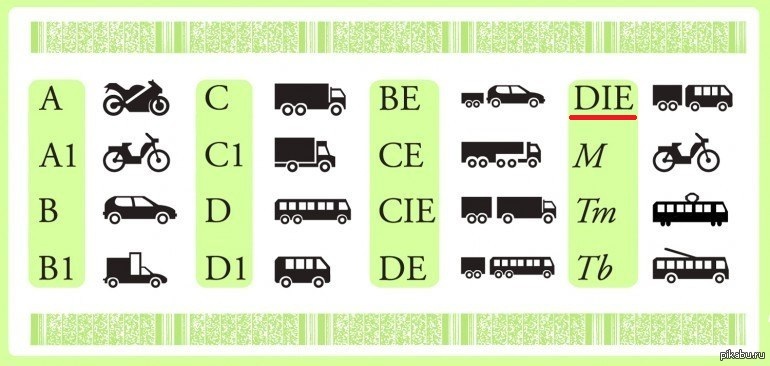 Thing (а именно thing.n.12 в WordNet) — это категория высокого уровня, которая включает такие категории, как часть тела и водоем . Декодированный временной ход всегда является промежуточным, и есть несколько случаев, когда вероятность декодирования была очень высокой или очень низкой. Точки времени, в которых предмет действительно присутствовал в стимуле, имеют лишь незначительно более высокие вероятности декодирования, чем моменты времени, в которых предмет не присутствовал.AUC 0,694 является статистически значимым, но он намного ниже, чем AUC, полученный для других категорий, представленных здесь. Это говорит о том, что кортикальное представление вещи не отличается от других, более специфических категорий. Мы считаем, что это потому, что вещь — это искусственная категория, изобретенная WordNet, которая не сильно представлена в мозгу.
Thing (а именно thing.n.12 в WordNet) — это категория высокого уровня, которая включает такие категории, как часть тела и водоем . Декодированный временной ход всегда является промежуточным, и есть несколько случаев, когда вероятность декодирования была очень высокой или очень низкой. Точки времени, в которых предмет действительно присутствовал в стимуле, имеют лишь незначительно более высокие вероятности декодирования, чем моменты времени, в которых предмет не присутствовал.AUC 0,694 является статистически значимым, но он намного ниже, чем AUC, полученный для других категорий, представленных здесь. Это говорит о том, что кортикальное представление вещи не отличается от других, более специфических категорий. Мы считаем, что это потому, что вещь — это искусственная категория, изобретенная WordNet, которая не сильно представлена в мозгу.
Характеристики декодирования для всех категорий
Результаты на Рисунке 3 показали, что декодер не одинаково успешен для всех категорий. Для дальнейшего изучения этой проблемы мы вычислили производительность декодирования (AUC) для всех категорий, которые появлялись как минимум в 3 временных точках в наборе данных проверки. На рисунке 4 мы показываем эти AUC в виде графика, организованного в соответствии со структурой семантической таксономии WordNet (аналогичные графики для каждого предмета в отдельности показаны на дополнительных рисунках 1–7; 30 наиболее декодируемых категорий по всем предметам перечислены в Дополнительная таблица 1). Здесь цвет каждого узла отражает AUC (интегрированный для всех субъектов), а насыщенность отражает уверенность в оценке AUC.
Для дальнейшего изучения этой проблемы мы вычислили производительность декодирования (AUC) для всех категорий, которые появлялись как минимум в 3 временных точках в наборе данных проверки. На рисунке 4 мы показываем эти AUC в виде графика, организованного в соответствии со структурой семантической таксономии WordNet (аналогичные графики для каждого предмета в отдельности показаны на дополнительных рисунках 1–7; 30 наиболее декодируемых категорий по всем предметам перечислены в Дополнительная таблица 1). Здесь цвет каждого узла отражает AUC (интегрированный для всех субъектов), а насыщенность отражает уверенность в оценке AUC.
Рисунок 4. Графическая визуализация точности декодирования . Сюжет оформлен в соответствии с графической структурой WordNet. Кружки и квадраты обозначают 479 категорий, представленных в фильмах, используемых для проверки модели. Кружки обозначают предметы (существительные), а квадраты обозначают действия (глаголы). Производительность декодирования была агрегирована по всем предметам путем объединения декодированных вероятностных временных курсов. Размер каждого маркера обозначает площадь под кривой ROC (AUC) для этой категории в диапазоне от 0.5 к 1.0. Цвета маркера обозначают значение p для AUC этой категории; более глубокий синий отражает большие значения p . Категории, для которых важна точность декодирования, отображаются закрашенными кружками (q (FDR) <0,01). AUC высок для некоторых общих категорий, таких как человек, млекопитающее и артефакт . Это низкий для других, таких как вещь, материя, инструментальность и абстракция . Это говорит о том, что некоторые общие категории хорошо представлены в мозгу в масштабе, который можно измерить с помощью фМРТ, а другие нет.AUC обычно низок для определенных категорий, которые встречаются реже. Это не обязательно означает, что нечастые категории плохо представлены в мозгу; он может просто отражать недостаточные данные. AUC также низка для фоновых категорий, таких как завод, местоположение и атмосферное явление . Это может происходить из-за того, что испытуемые обычно не уделяют должного внимания этим категориям, если это не указано явно.
Размер каждого маркера обозначает площадь под кривой ROC (AUC) для этой категории в диапазоне от 0.5 к 1.0. Цвета маркера обозначают значение p для AUC этой категории; более глубокий синий отражает большие значения p . Категории, для которых важна точность декодирования, отображаются закрашенными кружками (q (FDR) <0,01). AUC высок для некоторых общих категорий, таких как человек, млекопитающее и артефакт . Это низкий для других, таких как вещь, материя, инструментальность и абстракция . Это говорит о том, что некоторые общие категории хорошо представлены в мозгу в масштабе, который можно измерить с помощью фМРТ, а другие нет.AUC обычно низок для определенных категорий, которые встречаются реже. Это не обязательно означает, что нечастые категории плохо представлены в мозгу; он может просто отражать недостаточные данные. AUC также низка для фоновых категорий, таких как завод, местоположение и атмосферное явление . Это может происходить из-за того, что испытуемые обычно не уделяют должного внимания этим категориям, если это не указано явно. Подобные графики для каждого предмета в отдельности показаны на дополнительных рисунках 1–7.
Подобные графики для каждого предмета в отдельности показаны на дополнительных рисунках 1–7.
Многие общие категории, такие как человек, млекопитающее, общаются, и структура , были декодированы точно, что позволяет предположить, что эти категории представлены конкретными последовательными паттернами активности в мозге. Напротив, другие общие категории, такие как вещь и абстракция , были декодированы плохо, хотя мы можем точно декодировать гипонимы (или подчиненные категории) этих плохо декодированных общих категорий. Например, объект , объект декодируется плохо, но его гипонимы водоем и часть тела декодируются точно.Это говорит о том, что часть тела и водоем представлены очень по-разному, поэтому линейная модель не может декодировать обе категории одновременно. Среди действий (обозначенных квадратными маркерами) мы обнаружили, что коммуникативные глаголы, глаголы путешествия и непереходные движения (например, прыжок , поворот ) обычно значительно и точно декодировались, в то время как глаголы потребления и переходные движения (например, перетащить, залить ) ) обычно декодировались плохо.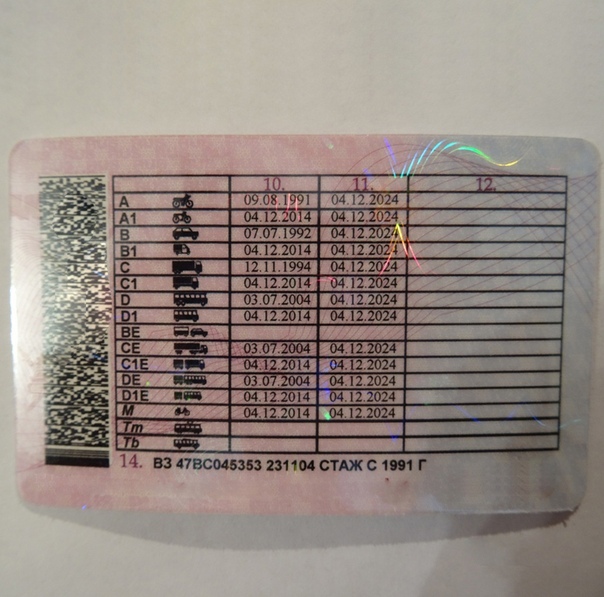
Производительность условного декодирования
Подход HLR предполагает, что корковые реакции соответствуют таксономии WordNet, но в некоторых случаях это предположение, вероятно, неверно.Поэтому мы провели анализ, который показывает, какие гипернимые связи в WordNet не отразились на активности мозга. В рамках подхода HLR мы использовали WordNet для построения условных моделей, которые декодируют наличие данной категории, включая все ее гипонимы. Например, условная модель для автомобиля должна различать любой автомобиль (например, универсал , спортивный автомобиль и т. Д.) И любой другой автомобиль . Эти модели неявно предполагают, что все гипонимы любой данной категории вызывают аналогичные реакции в коре головного мозга (рис. 5).Если это предположение верно, то общая производительность декодирования будет хорошей, но может быть трудно различить категории гипонимов. Если это предположение неверно, то общая производительность декодирования будет плохой, но будет легко различать гипонимы.
Рисунок 5. Условная AUC в сравнении с полной. HLR предполагает, что структура WordNet отражается в мозге. Однако это может быть не так. Если определенная группа категорий (показанная синими узлами в A ) сильно отражается в мозгу, то можно ожидать, что группа будет сильно отделима от всех других категорий.Эта ситуация показана графически в (B) , где воксельные ответы на несколько категорий нанесены на график в гипотетическом двухмерном пространстве ответов. Категории внутри группы отображаются синим цветом, а другие категории — серым. Воксельный ответ на категорию, которую мы пытаемся декодировать, показан кружком. Здесь синие категории легко линейно отделены от других категорий, что приводит к высокому общему показателю AUC для выбранной категории. Другая ситуация показана в (C) , где сгруппированные категории не вызывают очень похожих ответов.Здесь выбранную категорию легче отличить от ее братьев и сестер, чем от других категорий, что приводит к высокому cAUC и более низкому общему AUC. Это говорит о том, что для группировок категорий на основе WordNet, которые не отражаются в мозге, cAUC будет значительно выше, чем общая AUC.
Это говорит о том, что для группировок категорий на основе WordNet, которые не отражаются в мозге, cAUC будет значительно выше, чем общая AUC.
Мы использовали эту логику для построения теста для каждой гипернимой связи в подмножестве WordNet, используемом в этом исследовании. Для каждой категории мы вычислили условную AUC (cAUC), используя только моменты времени в наборе данных проверки, когда присутствовали все гиперонимы этой категории.Таким образом, cAUC показывает, насколько хорошо категорию можно отличить от своих братьев и сестер. Затем мы сравнили cAUC с общим AUC для каждой категории. Если cAUC была значительно выше, чем общая AUC, то мы пришли к выводу, что предполагаемая взаимосвязь между этой категорией и ее гипернимом не отражается на активности мозга.
Результаты этого анализа показаны на рисунке 6. Здесь cAUC для каждой категории нанесен на тот же график WordNet, что и на рисунке 4. Размер и цвет каждого узла отражает cAUC соответствующей категории.Для категорий, где cAUC значительно выше, чем общая AUC, граница, связывающая эту категорию с ее гиперонимом, окрашена в красный цвет (все значимые взаимосвязи перечислены в дополнительной таблице 2). В общей сложности мы обнаружили, что 17 отношений, представленных WordNet, существенно не соответствовали ответам мозга. Некоторые из существенно противоречивых отношений выделяют категории, которые технически связаны, но сильно отличаются от своих братьев и сестер. Например, растение — единственная неживая ветвь организма , лошадь — единственная лошадь, на которой ездят люди, а пингвин — единственная нелетающая морская птица .Между категориями очень высокого уровня появляются и другие существенно противоречивые отношения, вероятно, отражающие трудный выбор, сделанный при разработке WordNet. Например, отношения между thing (в частности, thing.n.12 ) и его гипонимами body part и body кажутся искусственными. В целом, эти результаты показывают несколько взаимосвязей категорий, которые следует пересмотреть, если WordNet будет использоваться для дальнейшего моделирования реакций мозга.
Рисунок 6.Графическая визуализация точности декодирования после кондиционирования родительских категорий . Производительность декодирования для каждой из 479 категорий, обусловленная присутствием их гиперонима в сцене, объединенная по предметам. Рисунок расположен так же, как на рисунке 4. Условная AUC (cAUC) была вычислена только в моменты времени, когда присутствуют гиперонимы категории, что заставляет модель различать родственные категории. Если cAUC для категории больше, чем полный AUC, это означает, что категорию легче отличить от своих братьев и сестер, чем от других категорий.Значимость этой разницы оценивалась для каждого ребра в графе WordNet. Если категория значительно меньше похожа на своих братьев и сестер, чем можно было бы ожидать, ее край окрашивается в красный цвет. Таким образом, связи WordNet между категориями, которые не связаны между собой в мозгу, отображаются красным. Края между предметом и его гипонимом водоем и частью тела отображаются красными, потому что эти категории не представлены одинаково в мозгу. Кроме того, граница между организмом и растением выглядит красной, вероятно, потому что растение является единственным неживым гипонимом организма .
Производительность декодирования для каждой из 479 категорий, обусловленная присутствием их гиперонима в сцене, объединенная по предметам. Рисунок расположен так же, как на рисунке 4. Условная AUC (cAUC) была вычислена только в моменты времени, когда присутствуют гиперонимы категории, что заставляет модель различать родственные категории. Если cAUC для категории больше, чем полный AUC, это означает, что категорию легче отличить от своих братьев и сестер, чем от других категорий.Значимость этой разницы оценивалась для каждого ребра в графе WordNet. Если категория значительно меньше похожа на своих братьев и сестер, чем можно было бы ожидать, ее край окрашивается в красный цвет. Таким образом, связи WordNet между категориями, которые не связаны между собой в мозгу, отображаются красным. Края между предметом и его гипонимом водоем и частью тела отображаются красными, потому что эти категории не представлены одинаково в мозгу. Кроме того, граница между организмом и растением выглядит красной, вероятно, потому что растение является единственным неживым гипонимом организма . (S (t) | R).Чтобы сравнить с уровнем производительности, который можно было бы ожидать случайно, мы нормализовали это значение на априорную вероятность фактических категорий: P 0 ( S ). Здесь мы аппроксимировали P 0 ( S i ), установив его равным доле времени, в течение которого категория S i присутствовала в фильмах, используемых для оценки параметров модели. . Таким образом, вероятность декодированной категории относительно предыдущей для каждого момента времени определяется выражением:
(S (t) | R).Чтобы сравнить с уровнем производительности, который можно было бы ожидать случайно, мы нормализовали это значение на априорную вероятность фактических категорий: P 0 ( S ). Здесь мы аппроксимировали P 0 ( S i ), установив его равным доле времени, в течение которого категория S i присутствовала в фильмах, используемых для оценки параметров модели. . Таким образом, вероятность декодированной категории относительно предыдущей для каждого момента времени определяется выражением:
На рис. 7 показана относительная логарифмическая вероятность во времени, усредненная по субъектам (аналогичные графики, показывающие данные для каждого субъекта отдельно, показаны на дополнительных рисунках 1–7).Логарифмические отношения правдоподобия больше нуля указывают периоды, когда оценки модели HLR относительно более вероятны, чем предыдущие, а логарифмические отношения меньше нуля указывают периоды, когда модель относительно менее вероятна, чем предыдущая. Этот рисунок показывает, что одни периоды в фильме декодируются лучше, чем другие. Изучение стимулов, появившихся во время пиков и спадов при декодировании, показывает, что декодирование наиболее точно для подводных сцен и сцен, в которых есть один человек.Эти сцены содержат только несколько категорий, каждая из которых хорошо смоделирована декодером. Мы наблюдаем слабую тенденцию к более низким относительным логарифмическим отношениям, когда количество категорий в сцене больше (см. Дополнительный рисунок 8), а декодирование относительно плохое для сцен, которые содержат необычные категории (например, сцена крупным планом, в которую наливают вино. бокал) и для временных точек, содержащих переходы между сценами.
Этот рисунок показывает, что одни периоды в фильме декодируются лучше, чем другие. Изучение стимулов, появившихся во время пиков и спадов при декодировании, показывает, что декодирование наиболее точно для подводных сцен и сцен, в которых есть один человек.Эти сцены содержат только несколько категорий, каждая из которых хорошо смоделирована декодером. Мы наблюдаем слабую тенденцию к более низким относительным логарифмическим отношениям, когда количество категорий в сцене больше (см. Дополнительный рисунок 8), а декодирование относительно плохое для сцен, которые содержат необычные категории (например, сцена крупным планом, в которую наливают вино. бокал) и для временных точек, содержащих переходы между сценами.
Рис. 7. Общая производительность декодирования в каждый момент времени для всех категорий объектов и действий .Здесь результаты в каждый момент времени были усреднены по всем пяти предметам. Точность декодирования выражается как логарифмическая вероятность фактических меток категорий для данной модели относительно априорной вероятности присутствия каждой категории. Значения, равные нулю, указывают на то, что модель работает так хорошо, как можно было бы ожидать, просто предполагая, основываясь на априорных вероятностях. Заштрихованные области показывают, что производительность значительно выше вероятности ( p <0,01 без исправлений, тест перестановки). Вверху показаны два примера хорошо декодированных моментов времени.На одном изображен идущий человек, на другом - подводная сцена, изображающая косяк рыб. Это простые и стереотипные сцены, которые можно точно декодировать. Внизу показаны два примера плохо декодированных моментов времени. Один представляет собой переход между сценами прыжка лошади и пьющей женщины, другой - крупным планом глаза оленя. Сцена перехода не может быть декодирована точно, потому что временная точность декодера плохая. Глаз оленя - нетипичная сцена, которая редко встречается в стимулах, используемых для оценки воксельных моделей.Подобные графики, показывающие данные по каждому предмету отдельно, показаны на дополнительных рисунках 1–7.
Значения, равные нулю, указывают на то, что модель работает так хорошо, как можно было бы ожидать, просто предполагая, основываясь на априорных вероятностях. Заштрихованные области показывают, что производительность значительно выше вероятности ( p <0,01 без исправлений, тест перестановки). Вверху показаны два примера хорошо декодированных моментов времени.На одном изображен идущий человек, на другом - подводная сцена, изображающая косяк рыб. Это простые и стереотипные сцены, которые можно точно декодировать. Внизу показаны два примера плохо декодированных моментов времени. Один представляет собой переход между сценами прыжка лошади и пьющей женщины, другой - крупным планом глаза оленя. Сцена перехода не может быть декодирована точно, потому что временная точность декодера плохая. Глаз оленя - нетипичная сцена, которая редко встречается в стимулах, используемых для оценки воксельных моделей.Подобные графики, показывающие данные по каждому предмету отдельно, показаны на дополнительных рисунках 1–7.
Сравнение оригинальных фильмов с декодированными категориями
Чтобы обеспечить интуитивно понятную и доступную демонстрацию производительности HLR-декодера, мы создали составное видео, которое показывает стимулирующий фильм слева и категории с наивысшей вероятностью декодирования справа (см. Дополнительное видео 1). Размер каждой метки соответствует прогнозируемой вероятности наличия категории.Обратите внимание, что показанные здесь стимулы взяты из набора для проверки модели и не использовались для обучения декодера. Эта демонстрация показывает, что декодер успешно восстанавливает информацию о многих категориях независимо от конкретного содержания фильма.
Отображение весов моделей декодирования в Cortex
Поскольку декодер HLR, кажется, способен восстанавливать многие категории объектов и действий из ЖИРНЫХ ответов, естественно может возникнуть вопрос, какие воксели используются для декодирования каждой категории.Однако обратите внимание, что результаты декодирования следует интерпретировать с осторожностью; вопрос о том, какие воксели участвуют в декодировании, не эквивалентен вопросу о том, какие воксели представляют информацию о категории (Haufe et al.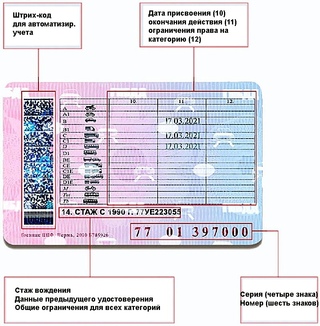 , 2014; Weichwald et al., 2015). Вокселы, которые имеют малые (или нулевые) веса декодирования для категории, могут по-прежнему представлять информацию об этой категории, но если воксель также представляет информацию о других категориях, то это может быть не особенно полезно для декодирования. И наоборот, вокселы, которые имеют большие веса декодирования, могут не представлять информацию о категории, а вместо этого могут быть коррелированы (или антикоррелированы) с шумом в вокселях, которые действительно представляют эту категорию.Эти проблемы интерпретации гораздо менее серьезны для моделей кодирования (Huth et al., 2012), которые предсказывают ответы на стимулы, а не предсказывают стимулы на основе ответов. Вокселы, которые имеют небольшие веса модели кодирования для категории, скорее всего, не участвуют в представлении этой категории. Вокселы, которые имеют большие веса модели кодирования, либо реагируют непосредственно на категорию, либо на какой-либо аспект стимула, который коррелирует с категорией.
, 2014; Weichwald et al., 2015). Вокселы, которые имеют малые (или нулевые) веса декодирования для категории, могут по-прежнему представлять информацию об этой категории, но если воксель также представляет информацию о других категориях, то это может быть не особенно полезно для декодирования. И наоборот, вокселы, которые имеют большие веса декодирования, могут не представлять информацию о категории, а вместо этого могут быть коррелированы (или антикоррелированы) с шумом в вокселях, которые действительно представляют эту категорию.Эти проблемы интерпретации гораздо менее серьезны для моделей кодирования (Huth et al., 2012), которые предсказывают ответы на стимулы, а не предсказывают стимулы на основе ответов. Вокселы, которые имеют небольшие веса модели кодирования для категории, скорее всего, не участвуют в представлении этой категории. Вокселы, которые имеют большие веса модели кодирования, либо реагируют непосредственно на категорию, либо на какой-либо аспект стимула, который коррелирует с категорией. По этим причинам мы направляем читателей, заинтересованных в том, как эти категории представлены в коре головного мозга, к нашему исследованию модели кодирования, в котором использовался тот же набор данных, что и анализируемый здесь (Huth et al., 2012).
По этим причинам мы направляем читателей, заинтересованных в том, как эти категории представлены в коре головного мозга, к нашему исследованию модели кодирования, в котором использовался тот же набор данных, что и анализируемый здесь (Huth et al., 2012).
Чтобы проиллюстрировать сложность интерпретации весов модели декодирования, мы нанесли веса декодирования и кодирования для одной категории, человек.n.01 , на плоские корковые карты для одного субъекта (Рисунок 8, Для иллюстративных целей эта модель декодирования была использована весь набор данных, а не только временные точки, содержащие гиперонимы человек ). Более ранние исследования показали, что некоторые области мозга выборочно реагируют на человеческие лица и тела, включая веретеновидную и затылочную области лица [FFA Kanwisher et al., 1997 г. и OFA Kanwisher et al., 1997; Halgren et al., 1999] и экстрастриарной области тела (EBA Downing et al., 2001). Поэтому можно наивно ожидать, что вокселям во всех этих областях будут присвоены большие положительные веса в модели декодирования для человек . Однако модель декодирования имеет большие веса только в областях лица (FFA и OFA), но не в области тела (EBA). Таким образом, прямая интерпретация весов модели декодирования приведет к выводу, что EBA не представляет информацию о людях.Напротив, модель кодирования имеет высокий вес в EBA, а также в областях лица, демонстрируя, что EBA, как и ожидалось, действительно реагирует на присутствие людей. Так почему же модель декодирования проигнорировала EBA? Одна возможность предлагается нашим более ранним исследованием модели кодирования, которое показало, что EBA реагирует как на животных, так и на людей, но что FFA и OFA относительно более избирательны для человеческих лиц (Huth et al., 2012). Основываясь на результатах этих моделей кодирования, вывод модели декодирования — что EBA не представляет информацию о людях — кажется ложным.Вместо этого мы должны сделать вывод, что EBA представляет информацию о людях в дополнение к другим категориям. Этот пример показывает, что прямая интерпретация весов декодирования может легко привести к ошибочным выводам, и поэтому его следует избегать, когда это возможно.
Однако модель декодирования имеет большие веса только в областях лица (FFA и OFA), но не в области тела (EBA). Таким образом, прямая интерпретация весов модели декодирования приведет к выводу, что EBA не представляет информацию о людях.Напротив, модель кодирования имеет высокий вес в EBA, а также в областях лица, демонстрируя, что EBA, как и ожидалось, действительно реагирует на присутствие людей. Так почему же модель декодирования проигнорировала EBA? Одна возможность предлагается нашим более ранним исследованием модели кодирования, которое показало, что EBA реагирует как на животных, так и на людей, но что FFA и OFA относительно более избирательны для человеческих лиц (Huth et al., 2012). Основываясь на результатах этих моделей кодирования, вывод модели декодирования — что EBA не представляет информацию о людях — кажется ложным.Вместо этого мы должны сделать вывод, что EBA представляет информацию о людях в дополнение к другим категориям. Этот пример показывает, что прямая интерпретация весов декодирования может легко привести к ошибочным выводам, и поэтому его следует избегать, когда это возможно.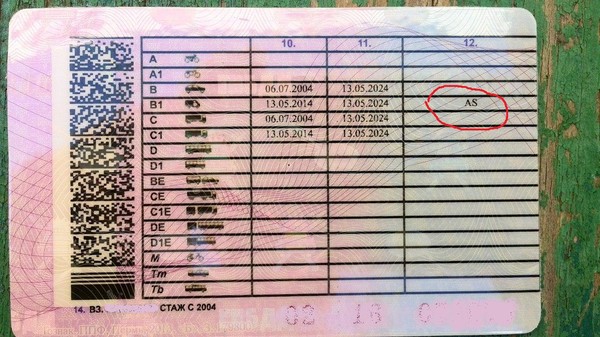 Вместо этого на вопросы о корковом представительстве следует отвечать, используя подходы кодирования.
Вместо этого на вопросы о корковом представительстве следует отвечать, используя подходы кодирования.
Рис. 8. Сглаженные кортикальные карты, показывающие пример веса модели декодирования и кодирования для одной категории . Мы построили графики веса моделей декодирования и кодирования для одной категории, 90–120 человек.№ 01 , по одной теме. Для этой визуализации мы построили модель прямого логистического декодирования для этой категории (т.е. мы не ставили условия для ее гиперонимов). Мы усреднили веса декодирования по трем задержкам в пределах каждого из 5000 вокселей, а затем изменили масштаб полученных средних весов, чтобы получить стандартное отклонение 1,0. Точно так же мы усреднили веса кодирования для тех же 5000 вокселей по трем задержкам, а затем изменили масштаб результатов. Для модели декодирования мы видим большие положительные веса в затылочной области лица (OFA) и веретенообразной области лица (FFA), предполагая, что активность в этих областях предсказывает присутствие человека в визуальной сцене. Для модели кодирования мы также видим положительные веса в OFA и FFA, но некоторые из наиболее положительных весов появляются в экстрастриарной области тела (EBA). Это говорит о том, что присутствие человека в визуальной сцене предсказывает реакцию EBA. Однако отсутствие больших весов EBA в модели декодирования предполагает, что ответы EBA не специфичны для наблюдения за человеком. Это иллюстрирует сложность, присущую интерпретации весов из модели декодирования.
Для модели кодирования мы также видим положительные веса в OFA и FFA, но некоторые из наиболее положительных весов появляются в экстрастриарной области тела (EBA). Это говорит о том, что присутствие человека в визуальной сцене предсказывает реакцию EBA. Однако отсутствие больших весов EBA в модели декодирования предполагает, что ответы EBA не специфичны для наблюдения за человеком. Это иллюстрирует сложность, присущую интерпретации весов из модели декодирования.
Обсуждение
В этом исследовании мы показали, что можно точно декодировать наличие или отсутствие многих категорий объектов и действий в естественных фильмах по жирным сигналам, измеренным с помощью фМРТ.К ним относятся общие категории, такие как животное и структура , конкретные категории, такие как собака и стена , и действия, такие как talk и run . Однако точность декодирования для одних категорий была лучше, чем для других. В частности, мы обнаружили, что точность декодирования в целом была лучше для сцен, содержащих относительно меньше категорий, чем для сцен, содержащих относительно большее количество категорий. Это говорит о том, что количество связанной с категорией информации, доступной в ЖИРНЫХ сигналах в каждый момент времени, ограничено.
Это говорит о том, что количество связанной с категорией информации, доступной в ЖИРНЫХ сигналах в каждый момент времени, ограничено.
Наш декодер использовал модель HLR, основанную на графической структуре WordNet, семантическую таксономию, которая была вручную построена группой лингвистов (Miller, 1995). Этот иерархический подход имеет две важные особенности, которые делают его привлекательным для декодирования категорий естественных стимулов. Во-первых, он предоставляет средства для одновременного декодирования информации с множеством разных уровней детализации. Это жизненно важно для декодирования естественных стимулов, когда неясно, какой уровень детализации следует использовать для описания любого конкретного объекта или действия.Например, один и тот же объект можно правильно обозначить как автомобиль , автомобиль, спортивный автомобиль или Ford Mustang . Посредством одновременного декодирования всех уровней детализации модель HLR обходит вопрос о том, какой уровень является наиболее подходящим: сцена с некоторой вероятностью содержит автомобиль , некоторая вероятность содержит автомобиль и так далее. Это позволяет модели HLR декодировать относительно более общие категории, когда определенные категории встречаются нечасто или когда их трудно различить с помощью данных мозга.Например, HLR может показать, что сложно декодировать конкретную категорию Ford Mustang , но легко декодировать автомобиль общей категории . Использование нескольких уровней детализации также позволяет HLR обобщать на новые категории: даже если Ford Mustang не появился в наборе данных оценки модели, HLR мог бы декодировать присутствие автомобиля на основе более ранних примеров этой категории.
Это позволяет модели HLR декодировать относительно более общие категории, когда определенные категории встречаются нечасто или когда их трудно различить с помощью данных мозга.Например, HLR может показать, что сложно декодировать конкретную категорию Ford Mustang , но легко декодировать автомобиль общей категории . Использование нескольких уровней детализации также позволяет HLR обобщать на новые категории: даже если Ford Mustang не появился в наборе данных оценки модели, HLR мог бы декодировать присутствие автомобиля на основе более ранних примеров этой категории.
Вторая важная особенность модели HLR состоит в том, что она использует отношения между категориями для рационального ограничения результатов декодирования.Если бы эти ограничения не были включены, одновременное декодирование иерархически связанных категорий могло бы легко привести к бессмысленным результатам. Например, простой одновременный декодер может обнаружить, что вероятность конкретной сцены, содержащей автомобиль , выше, чем вероятность этой сцены, содержащей автомобиль . Это было бы невозможно, так как каждый автомобиль также является автомобилем . HLR позволяет избежать этой проблемы, ограничивая вероятность декодирования любой категории не более чем равной вероятности декодирования гиперонимов этой категории в WordNet.Этот подход основан на идее, известной как «структурированный результат» или «иерархическое обучение» (DeCoro et al., 2007; Silla and Freitas, 2011), области машинного обучения, связанной с проблемами, в которых выходные данные, как известно, имеют определенные статистические данные. структура. В проблеме декодирования, которую мы здесь рассматриваем, структура вывода определяется иерархией категорий WordNet и знанием того, что категория никогда не может присутствовать, если не присутствуют ее гиперонимы. Эта информация включается в модель с использованием так называемой «местной» или «родственной» политики для выбора отрицательных обучающих примеров для каждой категории (Wiener et al., 1995; Силла и Фрейтас, 2011). Эта номенклатура исходит из того факта, что отрицательные примеры для каждой категории выбираются как моменты времени, когда присутствуют братья и сестры категории (и, следовательно, присутствует родитель категории), но где сама категория отсутствует.
Это было бы невозможно, так как каждый автомобиль также является автомобилем . HLR позволяет избежать этой проблемы, ограничивая вероятность декодирования любой категории не более чем равной вероятности декодирования гиперонимов этой категории в WordNet.Этот подход основан на идее, известной как «структурированный результат» или «иерархическое обучение» (DeCoro et al., 2007; Silla and Freitas, 2011), области машинного обучения, связанной с проблемами, в которых выходные данные, как известно, имеют определенные статистические данные. структура. В проблеме декодирования, которую мы здесь рассматриваем, структура вывода определяется иерархией категорий WordNet и знанием того, что категория никогда не может присутствовать, если не присутствуют ее гиперонимы. Эта информация включается в модель с использованием так называемой «местной» или «родственной» политики для выбора отрицательных обучающих примеров для каждой категории (Wiener et al., 1995; Силла и Фрейтас, 2011). Эта номенклатура исходит из того факта, что отрицательные примеры для каждой категории выбираются как моменты времени, когда присутствуют братья и сестры категории (и, следовательно, присутствует родитель категории), но где сама категория отсутствует. Этот подход также может сделать оценку модели более эффективной с точки зрения вычислений без снижения производительности, поскольку он использует только соответствующие обучающие примеры (Fagni and Sebastiani, 2007).
Этот подход также может сделать оценку модели более эффективной с точки зрения вычислений без снижения производительности, поскольку он использует только соответствующие обучающие примеры (Fagni and Sebastiani, 2007).
Одна потенциальная проблема с подходом HLR заключается в его неявном предположении, что все гипонимы категории вызывают сходные реакции мозга.Это может привести к проблемам, поскольку отношения категорий исходят из WordNet, которая представляет собой созданную вручную семантическую таксономию и, следовательно, не гарантирует отражения активности мозга. Чтобы решить эту проблему, мы протестировали каждую из взаимосвязей, указанных в подмножестве WordNet, охватываемом нашими стимулами. Это было сделано путем изучения того, насколько легко каждую категорию можно отличить от своих братьев и сестер по одному и тому же гиперониму.
Мы обнаружили, что два конкретных типа отношений WordNet не отражаются в корковых представлениях.Первые — это отношения, которые технически правильны, но в которых конкретная категория не может разделять многие функции с общей категорией.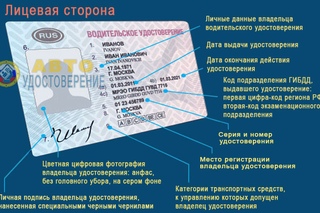 Например, взаимосвязь между растением и организмом не отражалась в мозговой деятельности, вероятно, потому, что растение является единственным неодушевленным гипонимом организма . Второй тип — это отношения, которые кажутся слишком академичными и могут быть характерны для WordNet. Например, отношения между штукой.№ 12 и его гипонимы часть тела и водоем не отражались в мозговой деятельности, вероятно, из-за того, что часть тела и водоем не относятся к аналогичным категориям по большинству показателей. Возможно, изменение иерархии WordNet путем удаления или изменения этих плохо представленных отношений на самом деле улучшит производительность декодирования. Изменение WordNet на основе данных мозга также может оказаться полезным для понимания того, как категории представлены в мозге.В будущих исследованиях можно даже заменить WordNet иерархией, полностью изученной на основе данных мозга. Попытки построить иерархию категорий непосредственно на основе данных мозга уже дали правдоподобные результаты для нескольких категорий (Kriegeskorte et al.
Например, взаимосвязь между растением и организмом не отражалась в мозговой деятельности, вероятно, потому, что растение является единственным неодушевленным гипонимом организма . Второй тип — это отношения, которые кажутся слишком академичными и могут быть характерны для WordNet. Например, отношения между штукой.№ 12 и его гипонимы часть тела и водоем не отражались в мозговой деятельности, вероятно, из-за того, что часть тела и водоем не относятся к аналогичным категориям по большинству показателей. Возможно, изменение иерархии WordNet путем удаления или изменения этих плохо представленных отношений на самом деле улучшит производительность декодирования. Изменение WordNet на основе данных мозга также может оказаться полезным для понимания того, как категории представлены в мозге.В будущих исследованиях можно даже заменить WordNet иерархией, полностью изученной на основе данных мозга. Попытки построить иерархию категорий непосредственно на основе данных мозга уже дали правдоподобные результаты для нескольких категорий (Kriegeskorte et al. , 2008).
, 2008).
Одной из альтернатив подхода HLR могло бы быть декодирование только категорий «базового уровня» (Rosch et al., 1976). Это упростило бы некоторые аспекты моделирования, поскольку избавило бы от необходимости учитывать отношения между категориями.Кроме того, категории базового уровня могут быть лучше представлены в коре головного мозга, чем категории высшего или подчиненного уровня (Iordan et al., 2015). Однако декодер базового уровня не будет таким мощным, как декодер HLR. Во-первых, категория базового уровня конкретного объекта сильно зависит от контекста (Rosch, 1978). Например, наблюдатели могут согласиться с тем, что категория базового уровня для определенного объекта в городской сцене — это автомобиль , но тот же самый объект, который видели в автосалоне, можно было бы назвать спортивным автомобилем .Неясно, имеет ли смысл в этой ситуации оценивать отдельные модели декодирования для автомобиля и спорткара . Во-вторых, для декодера категорий базового уровня было бы невозможно обобщить на новые категории. Например, предположим, что несколько сцен в наборе данных проверки содержали поездов , но эти поезда не появились в наборе данных оценки. В то время как ни модель HLR, ни декодер базового уровня не смогут напрямую декодировать присутствие поезда , модель HLR может быть способна декодировать присутствие транспортного средства на основе других примеров, таких как автомобили, лодки и самолеты.
Например, предположим, что несколько сцен в наборе данных проверки содержали поездов , но эти поезда не появились в наборе данных оценки. В то время как ни модель HLR, ни декодер базового уровня не смогут напрямую декодировать присутствие поезда , модель HLR может быть способна декодировать присутствие транспортного средства на основе других примеров, таких как автомобили, лодки и самолеты.
Другой альтернативой модели HLR могло бы быть представление категорий не как бинарных переменных, а как векторов признаков, вероятностей темы (Stansbury et al., 2013) или значений совместной встречаемости из больших текстовых корпусов (Mitchell et al., 2008 ; Turney, Pantel, 2010; Wehbe et al., 2014; Huth et al., 2016). Этот тип модели будет иметь несколько преимуществ перед двоичными декодерами. Во-первых, основанный на признаках декодер может улучшить обобщение, потому что он потребует только, чтобы все признаки присутствовали в стимуле оценки, и не обязательно, чтобы присутствовала каждая отдельная категория.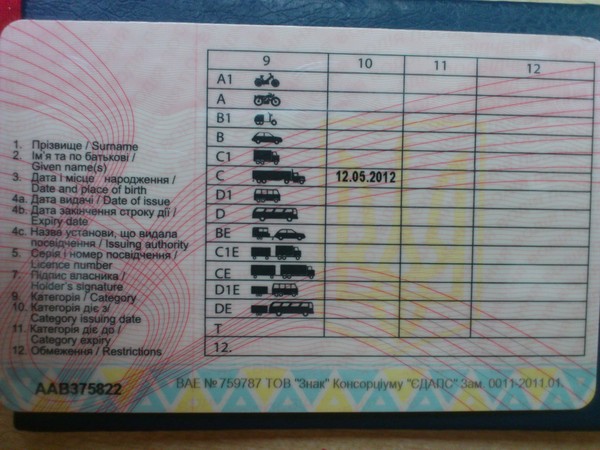 Во-вторых, модель HLR предполагает, что каждая категория не зависит от любой другой категории с учетом ее гиперонимов. Это предположение явно неверно во многих случаях (Blei et al., 2003; Stansbury et al., 2013). Например, хотя car и road являются дальними родственниками в таксономии WordNet, они сильно коррелируют в естественных стимулах. Декодер, учитывающий эти статистические взаимосвязи, может комбинировать информацию из категорий, которые не связаны напрямую в таксономии WordNet, что потенциально может улучшить производительность декодирования.
Во-вторых, модель HLR предполагает, что каждая категория не зависит от любой другой категории с учетом ее гиперонимов. Это предположение явно неверно во многих случаях (Blei et al., 2003; Stansbury et al., 2013). Например, хотя car и road являются дальними родственниками в таксономии WordNet, они сильно коррелируют в естественных стимулах. Декодер, учитывающий эти статистические взаимосвязи, может комбинировать информацию из категорий, которые не связаны напрямую в таксономии WordNet, что потенциально может улучшить производительность декодирования.
В последние годы область чтения мозга вызвала значительный интерес как у ученых, так и у общественности. Каждое усовершенствование технологии измерения мозга приближает нас к цели создания универсального устройства для считывания состояния мозга человека. С этой целью разработанная здесь модель HLR улучшила нашу способность одновременно декодировать множество переменных, соблюдая при этом некоторые статистические зависимости между ними. Тем не менее, многие проблемы, связанные с чтением мозга, остаются нерешенными.Мы считаем, что наиболее важным теоретическим ограничением является то, что все современные методы (включая HLR) предполагают независимость между переменными, которые фактически не являются независимыми. Одним из примеров является предположение, что каждая категория в сцене возникает независимо, как обсуждалось выше. Другой пример — предположение, что стимулы независимы от момента времени к моменту времени. Ослабление этих предположений должно улучшить производительность будущих декодеров мозга. Будущий идеальный декодер должен улавливать как можно больше этих зависимостей между переменными стимула, тем самым сводя к минимуму количество информации, необходимой для декодирования стимулов.
Тем не менее, многие проблемы, связанные с чтением мозга, остаются нерешенными.Мы считаем, что наиболее важным теоретическим ограничением является то, что все современные методы (включая HLR) предполагают независимость между переменными, которые фактически не являются независимыми. Одним из примеров является предположение, что каждая категория в сцене возникает независимо, как обсуждалось выше. Другой пример — предположение, что стимулы независимы от момента времени к моменту времени. Ослабление этих предположений должно улучшить производительность будущих декодеров мозга. Будущий идеальный декодер должен улавливать как можно больше этих зависимостей между переменными стимула, тем самым сводя к минимуму количество информации, необходимой для декодирования стимулов.
Авторские взносы
AH и TL разработали и выполнили анализ при участии NB, JG, SN и AV. AH, NB, AV и SN собрали данные. СН разработал стимул. AH пометил семантические категории в стимуле. AH и TL написали статью при участии NB, SN, JG и AV. JG курировал все этапы исследования.
JG курировал все этапы исследования.
Заявление о конфликте интересов
Авторы заявляют, что исследование проводилось в отсутствие каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Благодарности
Мы хотели бы поблагодарить Джеймса Гао и Толгу Чукур за их помощь в этом проекте. Работа была поддержана грантами Национального института глаз (EY019684), Центра науки информации (CSoI) и Научно-технологического центра NSF в рамках грантового соглашения CCF-0939370. AH также был поддержан нейролингвистическим сообществом Уильяма Орра Дингуолла.
Дополнительные материалы
Дополнительные материалы к этой статье можно найти в Интернете по адресу: https: // www.frontiersin.org/article/10.3389/fnsys.2016.00081
Список литературы
Бенджамини Ю. и Хохберг Ю. (1995). Контроль ложного обнаружения: практичный и эффективный подход к множественному тестированию. J. R. Stat. Soc. Сер. В . 57, 289–300.
J. R. Stat. Soc. Сер. В . 57, 289–300.
Google Scholar
Блей, Д. М., Нг, А. Ю. и Джордан, М. И. (2003). Скрытое размещение Дирихле. J. Mach. Учиться. Res. 3, 993–1022.
Google Scholar
Буткраджанг, Дж., и Кабан, А. (2012). Метка-шум Робастная логистическая регрессия и ее приложения . Lect Notes Comput Sci (включая Subser Lect Notes Artif Intell Lect Notes Bioinformatics) 7523 LNAI, 143–158.
Бойнтон, Г. М., Энгель, С. А., Гловер, Г. Х., Хигер, Д. Дж. (1996). Анализ линейных систем функциональной магнитно-резонансной томографии у человека V1. J. Neurosci. 16, 4207–4221.
PubMed Аннотация | Google Scholar
Карлсон, Т.А., Шратер, П., и Он, С. (2003). Паттерны деятельности в категориальных представлениях предметов. J. Cogn. Neurosci. 15, 704–717. DOI: 10.1162 / jocn.2003.15.5.704
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Кокс, Д. Д. и Савой, Р. Л. (2003). Функциональная магнитно-резонансная томография (фМРТ) «чтение мозга»: обнаружение и классификация распределенных паттернов активности фМРТ в зрительной коре головного мозга человека. Neuroimage 19, 261–270. DOI: 10.1016 / S1053-8119 (03) 00049-1
Л. (2003). Функциональная магнитно-резонансная томография (фМРТ) «чтение мозга»: обнаружение и классификация распределенных паттернов активности фМРТ в зрительной коре головного мозга человека. Neuroimage 19, 261–270. DOI: 10.1016 / S1053-8119 (03) 00049-1
PubMed Аннотация | CrossRef Полный текст | Google Scholar
ДеКоро, К., Баруткуоглу, З., Фибринк, Р. (2007). «Байесовское агрегирование для иерархической классификации жанров», в ISMIR (Вена).
Google Scholar
Даунинг, П. Э., Цзян, Ю., Шуман, М., и Канвишер, Н. (2001). Область коры, отобранная для визуальной обработки человеческого тела. Science 293, 2470–2473. DOI: 10.1126 / science.1063414
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Fagni, T., and Sebastiani, F. (2007).«О выборе отрицательных примеров для иерархической категоризации текста», Proceedings 3rd Lang Technology Conference (Poznan), 24–28.
Google Scholar
Халгрен, Э. , Дейл, А. М., Серено, М. И., Тутелл, Р. Б., Маринкович, К., и Розен, Б. Р. (1999). Расположение избирательной коры человеческого лица по отношению к ретинотопным областям. Хум. Brain Mapp. 7, 29–37.
, Дейл, А. М., Серено, М. И., Тутелл, Р. Б., Маринкович, К., и Розен, Б. Р. (1999). Расположение избирательной коры человеческого лица по отношению к ретинотопным областям. Хум. Brain Mapp. 7, 29–37.
PubMed Аннотация | Google Scholar
Haufe, S., Meinecke, F., Görgen, K., Dähne, S., Haynes, J.D., Haynes, J.-D., et al. (2014). Об интерпретации весовых векторов линейных моделей в многомерной нейровизуализации. Neuroimage 87, 96–110. DOI: 10.1016 / j.neuroimage.2013.10.067
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хэксби, Дж. В., Гоббини, М. И., Фьюри, М. Л., Ишаи, А., Схоутен, Дж. Л., и Пьетрини, П. (2001). Распределенные и перекрывающиеся изображения лиц и предметов в вентральной височной коре. Science 293, 2425–2430. DOI: 10.1126 / science.1063736
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хут, А.Г., Де Хеер, В.А., Гриффитс, Т.Л., Теуниссен, Ф.Э., и Джек, Л. (2016). Естественная речь раскрывает семантические карты, покрывающие кору головного мозга человека. Nature 532, 453–458. DOI: 10.1038 / nature17637
Nature 532, 453–458. DOI: 10.1038 / nature17637
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хут, А.Г., Нисимото, С., Ву, А.Т., и Галлант, Дж.Л. (2012). Непрерывное семантическое пространство описывает представление тысяч категорий объектов и действий в человеческом мозгу. Neuron 76, 1210–1224. DOI: 10.1016 / j.neuron.2012.10.014
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Иордан, М., Грин, М., Бек, Д., и Ли, Ф. (2015). Структура категорий базового уровня постепенно проявляется в вентральной зрительной коре человека. J. Cogn. Neurosci . 27, 1426–1446. DOI: 10.1162 / jocn_a_00790
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Канвишер, Н., Макдермотт Дж. И Чун М. М. (1997). Веретенообразная область лица: модуль в экстрастриальной коре головного мозга человека, специализирующийся на восприятии лица. J. Neurosci. 17, 4302–4311.
PubMed Аннотация | Google Scholar
Kriegeskorte, N. , Mur, M., Ruff, D. A., Kiani, R., Bodurka, J., Esteky, H., et al. (2008). Сопоставление категориальных представлений объектов в нижней височной коре человека и обезьяны. Нейрон 60, 1126–1141. DOI: 10.1016 / j.neuron.2008.10.043
, Mur, M., Ruff, D. A., Kiani, R., Bodurka, J., Esteky, H., et al. (2008). Сопоставление категориальных представлений объектов в нижней височной коре человека и обезьяны. Нейрон 60, 1126–1141. DOI: 10.1016 / j.neuron.2008.10.043
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Митчелл, Т.М., Шинкарева, С. В., Карлсон, А., Чанг, К.-М., Малав, В. Л., Мейсон, Р. А. и др. (2008). Прогнозирование активности мозга человека, связанной со значениями существительных. Science 320, 1191–1195. DOI: 10.1126 / science.1152876
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Населарис, Т., Пренгер, Р. Дж., Кей, К. Н., Оливер, М., и Галлант, Дж. Л. (2009). Байесовская реконструкция естественных изображений по активности мозга человека. Нейрон 63, 902–915.DOI: 10.1016 / j.neuron.2009.09.006
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Нисимото, С., Ву, А. Т., Населарис, Т., Бенджамини, Ю. , Ю., Б., и Галлант, Дж. Л. (2011). Реконструкция визуальных впечатлений от мозговой активности, вызванной естественными фильмами. Curr. Биол. 21, 1641–1646. DOI: 10.1016 / j.cub.2011.08.031
, Ю., Б., и Галлант, Дж. Л. (2011). Реконструкция визуальных впечатлений от мозговой активности, вызванной естественными фильмами. Curr. Биол. 21, 1641–1646. DOI: 10.1016 / j.cub.2011.08.031
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Педрегоса, Ф., Вароко, Г., Грамфор, А., Мишель, В., Тирион, Б., Grisel, O., et al. (2011). Scikit-learn: машинное обучение на Python. J. Mach. Учиться. Res. 12, 2825–2830.
Google Scholar
Рош, Э. (1978). «Принципы категоризации» в Познание и категоризация , ред. Э. Рош и Б. Ллойд (Хиллсдейл, Нью-Джерси: Лоуренс Эрлбаум), 27–48.
Рош Э., Мервис К. Б., Грей У. Д., Джонсон Д. М. и Бойс-Брем П. (1976). Основные объекты в природных категориях. Cogn. Psychol. 8, 382–439.DOI: 10.1016 / 0010-0285 (76)
-XCrossRef Полный текст
Силла, К. Н., Фрейтас, А. А. (2011). Обзор иерархической классификации по различным доменам приложений. Данные Мин. Знай. Discov. 22, 31–72. DOI: 10.1007 / s10618-010-0175-9
Знай. Discov. 22, 31–72. DOI: 10.1007 / s10618-010-0175-9
CrossRef Полный текст | Google Scholar
Стэнсбери Д. Э., Населарис Т. и Галлант Дж. Л. (2013). Статистика естественных сцен учитывает представление категорий сцен в зрительной коре головного мозга человека. Нейрон 79, 1025–1034. DOI: 10.1016 / j.neuron.2013.06.034
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Терни П. Д., Пантел П. (2010). От частоты к значению: векторные пространственные модели семантики. J. Artif. Intell. Res. 37, 141–188. DOI: 10.1613 / jair.2934
CrossRef Полный текст | Google Scholar
Ван Эссен, Д. К., Друри, Х. А., Диксон, Дж., Харвелл, Дж., Хэнлон, Д., и Андерсон, К. Х. (2001). Интегрированный программный комплекс для поверхностного анализа коры головного мозга. J. Am. Med. Сообщить. Доц. 8, 443–459. DOI: 10.1136 / jamia.2001.0080443
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Wehbe, L. , Murphy, B., Talukdar, P., Fyshe, A., Ramdas, A., and Mitchell, T. (2014). Одновременное выявление паттернов областей мозга, участвующих в различных подпроцессах чтения рассказов. PLoS ONE 9: e112575. DOI: 10.1371 / journal.pone.0112575
, Murphy, B., Talukdar, P., Fyshe, A., Ramdas, A., and Mitchell, T. (2014). Одновременное выявление паттернов областей мозга, участвующих в различных подпроцессах чтения рассказов. PLoS ONE 9: e112575. DOI: 10.1371 / journal.pone.0112575
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Weichwald, S., Мейер, Т., Озденицци, О., Шёлкопф, Б., и Болл, Т. Гросс-Вентруп, М. (2015). Правила причинной интерпретации для моделей кодирования и декодирования в нейровизуализации. Neuroimage 110, 48–59. DOI: 10.1016 / j.neuroimage.2015.01.036
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Винер, Э. Д., Педерсен, Дж. О., и Вейгенд, А. С. (1995). «Нейросетевой подход к определению тем», в материалах Proceedings of SDAIR-95, 4-го ежегодного симпозиума по анализу документов и поиску информации, , (Лас-Вегас, Невада), 317–332.
Google Scholar
Нейронные механизмы контроля внимания для объектов: декодирование альфа-канала ЭЭГ при прогнозировании лиц, сцен и инструментов альфа указывает на очаговое корковое усиление и повышенное альфа указывает на подавление.
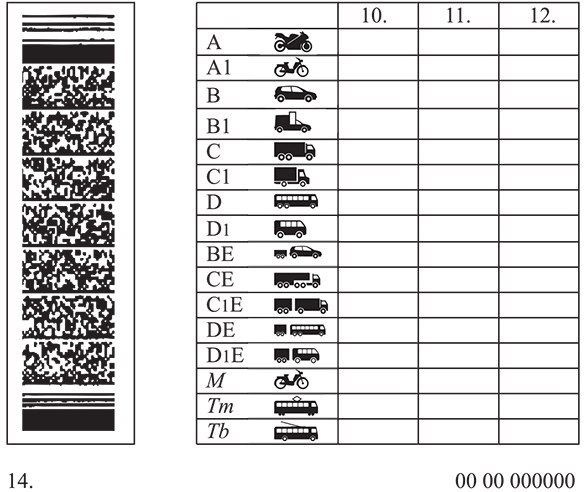 Это наблюдалось для пространственного избирательного внимания и внимания к характеристикам стимула, таким как цвет по сравнению с движением.Мы исследовали, включает ли внимание к объектам подобные альфа-опосредованные изменения фокальной корковой возбудимости. В эксперименте 1 20 добровольцев (8 мужчин; 12 женщин) были направлены (прогноз 80%) на пробную основу к различным объектам (лицам, сценам или инструментам). Поддержка векторного машинного декодирования альфа-паттернов мощности показала, что на поздней стадии (задержка> 500 мс) в предварительном периоде от метки к цели только альфа ЭЭГ различалась с категорией объекта, подлежащего наблюдению. В эксперименте 2, чтобы исключить возможность того, что расшифровка физических характеристик сигналов привела к нашим результатам, 25 участников (9 мужчин; 16 женщин) выполнили аналогичную задачу, в которой сигналы не предсказывали категорию объекта.Альфа-декодирование теперь было значимым только в раннем (<200 мс) предварительном периоде. В эксперименте 3, чтобы исключить возможность того, что различия в постановке задач между разными категориями объектов привели к результатам нашего эксперимента 1, 12 участников (5 мужчин; 7 женщин) выполнили задачу прогнозирования, в которой задача распознавания для разных объектов была идентична для разных категорий объектов.
Это наблюдалось для пространственного избирательного внимания и внимания к характеристикам стимула, таким как цвет по сравнению с движением.Мы исследовали, включает ли внимание к объектам подобные альфа-опосредованные изменения фокальной корковой возбудимости. В эксперименте 1 20 добровольцев (8 мужчин; 12 женщин) были направлены (прогноз 80%) на пробную основу к различным объектам (лицам, сценам или инструментам). Поддержка векторного машинного декодирования альфа-паттернов мощности показала, что на поздней стадии (задержка> 500 мс) в предварительном периоде от метки к цели только альфа ЭЭГ различалась с категорией объекта, подлежащего наблюдению. В эксперименте 2, чтобы исключить возможность того, что расшифровка физических характеристик сигналов привела к нашим результатам, 25 участников (9 мужчин; 16 женщин) выполнили аналогичную задачу, в которой сигналы не предсказывали категорию объекта.Альфа-декодирование теперь было значимым только в раннем (<200 мс) предварительном периоде. В эксперименте 3, чтобы исключить возможность того, что различия в постановке задач между разными категориями объектов привели к результатам нашего эксперимента 1, 12 участников (5 мужчин; 7 женщин) выполнили задачу прогнозирования, в которой задача распознавания для разных объектов была идентична для разных категорий объектов. . Результаты воспроизведены в эксперименте 1. В совокупности эти результаты подтверждают гипотезу о том, что нейронные механизмы зрительного избирательного внимания включают фокальные корковые изменения альфа-мощности не только для простого пространственного и особенного внимания, но и для объектного внимания высокого уровня у людей.
. Результаты воспроизведены в эксперименте 1. В совокупности эти результаты подтверждают гипотезу о том, что нейронные механизмы зрительного избирательного внимания включают фокальные корковые изменения альфа-мощности не только для простого пространственного и особенного внимания, но и для объектного внимания высокого уровня у людей. ЗНАЧИМОЕ ЗАЯВЛЕНИЕ Внимание — это когнитивная функция, которая позволяет выбирать релевантную информацию из сенсорных входных данных, чтобы ее можно было обработать для поддержки целенаправленного поведения. Зрительное внимание широко изучается, но нейронные механизмы, лежащие в основе отбора визуальной информации, остаются неясными. Колебательная активность ЭЭГ в альфа-диапазоне (8–12 Гц) нейронных популяций, восприимчивых к целевым визуальным стимулам, может быть частью механизма, поскольку считается, что альфа отражает фокальную нервную возбудимость.Здесь мы показываем, что активность альфа-диапазона, измеренная с помощью ЭЭГ кожи головы участников, варьируется в зависимости от конкретной категории объекта, выбранного вниманием. Это открытие подтверждает гипотезу о том, что активность альфа-диапазона является фундаментальным компонентом нейронных механизмов внимания.
Это открытие подтверждает гипотезу о том, что активность альфа-диапазона является фундаментальным компонентом нейронных механизмов внимания.
Введение
Селективное внимание — это фундаментальная когнитивная способность, которая облегчает обработку релевантной для задачи перцепционной информации и подавляет отвлекающие сигналы. Влияние внимания на восприятие было продемонстрировано в улучшении поведенческих характеристик (Posner, 1980) и изменении кривых психофизической настройки (Carrasco and Barbot, 2019).У людей эти перцептивные преимущества для наблюдаемых стимулов сочетаются с повышенными сенсорно-вызванными потенциалами (Van Voorhis and Hillyard, 1977; Eason, 1981; Mangun and Hillyard, 1991; Eimer, 1996; Luck et al., 2000) и повышением гемодинамики ответы (Corbetta et al., 1990; Heinze et al., 1994; Mangun et al., 1998; Tootell et al., 1998; Martínez et al., 1999; Hopfinger et al., 2000; Giesbrecht et al., 2003). ). У животных электрофизиологические записи показывают, что сенсорные нейроны, реагирующие на обслуживаемые раздражители, имеют более высокую частоту возбуждения, чем таковые на необслуживаемые раздражители (Moran and Desimone, 1985; Luck et al. , 1997), улучшенное соотношение сигнал-шум при передаче информации (Mitchell et al., 2009; Briggs et al., 2013) и повышенные колебательные ответы (Fries et al., 2001), которые поддерживают более высокую межреальную функциональную связь (Bosman et al. др., 2012).
, 1997), улучшенное соотношение сигнал-шум при передаче информации (Mitchell et al., 2009; Briggs et al., 2013) и повышенные колебательные ответы (Fries et al., 2001), которые поддерживают более высокую межреальную функциональную связь (Bosman et al. др., 2012).
Большинство моделей избирательного внимания постулируют, что нисходящие управляющие сигналы внимания, возникающие в корковых сетях более высокого уровня, искажают обработку сенсорных систем (Nobre et al., 1997; Kastner et al., 1999; Corbetta et al., 2000; Hopfinger et al., 2000; Corbetta, Shulman, 2002; Petersen, Posner, 2012).Однако остается неясным, как именно нисходящие сигналы влияют на сенсорную обработку в сенсорной коре. Один из возможных механизмов включает модуляцию альфа-колебаний ЭЭГ (8–12 Гц). Когда скрытое внимание направлено на одну сторону поля зрения, альфа-сигнал сильнее подавляется в противоположном полушарии (Worden et al., 2000; Sauseng et al., 2005; Thut et al., 2006; Rajagovindan and Ding, 2011). Считается, что это латерализованное уменьшение альфа-канала отражает увеличение возбудимости коры головного мозга в сенсорных нейронах, соответствующих задаче, для облегчения обработки предстоящих стимулов (Romei et al.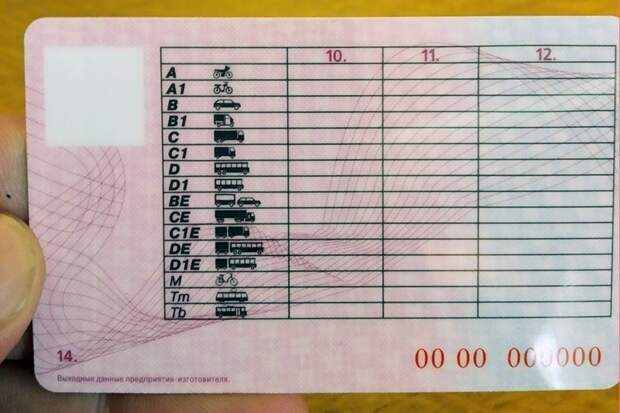 , 2008; Дженсен и Мазахери, 2010; Климеш, 2012). Связь между нисходящей активностью в лобно-теменной системе контроля внимания и альфа в сенсорной коре была предположена в исследованиях с использованием транскраниальной магнитной стимуляции для контроля областей (Capotosto et al., 2009, 2017), одновременных исследованиях ЭЭГ-фМРТ (Zumer et al., 2014; Liu et al., 2016) и магнитоэнцефалографии (Popov et al., 2017).
, 2008; Дженсен и Мазахери, 2010; Климеш, 2012). Связь между нисходящей активностью в лобно-теменной системе контроля внимания и альфа в сенсорной коре была предположена в исследованиях с использованием транскраниальной магнитной стимуляции для контроля областей (Capotosto et al., 2009, 2017), одновременных исследованиях ЭЭГ-фМРТ (Zumer et al., 2014; Liu et al., 2016) и магнитоэнцефалографии (Popov et al., 2017).
Хотя большинство исследований роли альфа в избирательном зрительном внимании сосредоточено на пространственном внимании, альфа-механизмы могут быть более общими (Jensen and Mazaheri, 2010).Селективное внимание к низкоуровневым визуальным характеристикам — движению по сравнению с цветом — также, как было показано, модулирует альфа, которая была локализована в областях MT и V4 с использованием моделирования ЭЭГ у людей (Snyder and Foxe, 2010). Следовательно, похоже, что связанная с вниманием альфа-модуляция может происходить на нескольких ранних уровнях сенсорной обработки в зрительной системе, причем локус альфа-модуляции функционально соответствует типу визуальной информации, на которую нацелено внимание. Неизвестно, участвует ли альфа-механизм также в контроле внимания над более высокими уровнями корковой визуальной обработки, такими как внимание к объектам.В настоящем исследовании мы проверили гипотезу о том, что альфа-модуляция является механизмом избирательного внимания к объектам путем записи ЭЭГ участников, выполняющих задачу упреждающего внимания к объекту, с использованием следующих трех категорий объектов: лица, сцены и инструменты. Используя методы декодирования ЭЭГ, мы подтверждаем эту гипотезу, обнаруживая объектно-специфические модуляции альфа-канала во время упреждающего внимания к различным категориям объектов.
Неизвестно, участвует ли альфа-механизм также в контроле внимания над более высокими уровнями корковой визуальной обработки, такими как внимание к объектам.В настоящем исследовании мы проверили гипотезу о том, что альфа-модуляция является механизмом избирательного внимания к объектам путем записи ЭЭГ участников, выполняющих задачу упреждающего внимания к объекту, с использованием следующих трех категорий объектов: лица, сцены и инструменты. Используя методы декодирования ЭЭГ, мы подтверждаем эту гипотезу, обнаруживая объектно-специфические модуляции альфа-канала во время упреждающего внимания к различным категориям объектов.
Материалы и методы
Обзор
Настоящее исследование состояло из трех экспериментов.Эксперимент 1 является основным экспериментом, в котором мы проверяли, можно ли различить топологию альфа-диапазона ЭЭГ в зависимости от объектно-ориентированного состояния внимания. Анализ данных ЭЭГ включал построение топографической карты разности мощностей и декодирование мощности альфа-диапазона опорным вектором (SVM) для количественной оценки того, содержит ли альфа-диапазон ЭЭГ информацию о наблюдаемой категории объекта.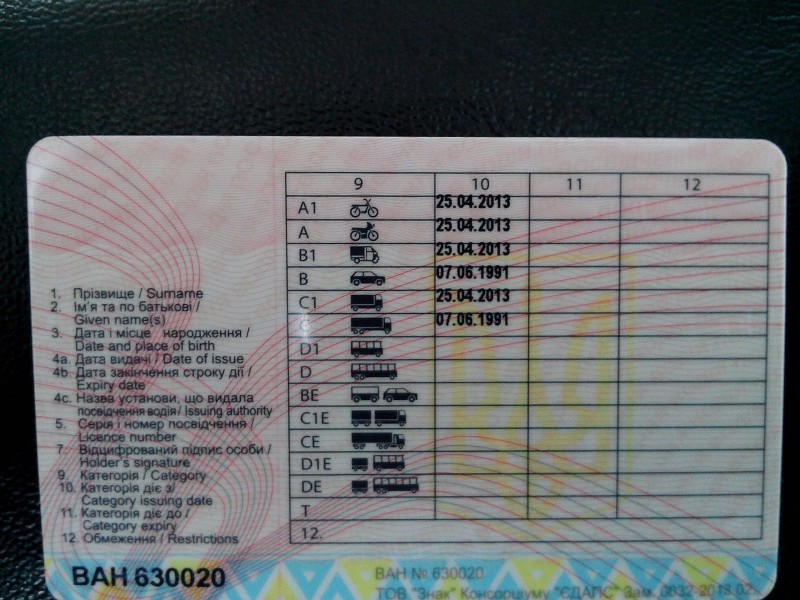 В экспериментах 2 и 3 мы проверили две альтернативные интерпретации наших результатов из эксперимента 1.В частности, в эксперименте 2 мы проверили, могла ли точность декодирования в подготовительном периоде между началом сигнала и целевым началом, обнаруженная в эксперименте 1, быть основана на различиях в сенсорных процессах, вызываемых в зрительной системе разными стимулами сигнала, поскольку физические стимульные свойства реплик для трех различных условий внимания объекта отличались друг от друга (треугольник против квадрата против круга). В эксперименте 3 мы исследовали, могли ли различия в альфа-топографии в разных условиях внимания к объекту в эксперименте 1 быть результатом различных наборов задач в трех условиях внимания объекта, а не отражением механизмов внимания на основе объектов в зрительной коре головного мозга.
В экспериментах 2 и 3 мы проверили две альтернативные интерпретации наших результатов из эксперимента 1.В частности, в эксперименте 2 мы проверили, могла ли точность декодирования в подготовительном периоде между началом сигнала и целевым началом, обнаруженная в эксперименте 1, быть основана на различиях в сенсорных процессах, вызываемых в зрительной системе разными стимулами сигнала, поскольку физические стимульные свойства реплик для трех различных условий внимания объекта отличались друг от друга (треугольник против квадрата против круга). В эксперименте 3 мы исследовали, могли ли различия в альфа-топографии в разных условиях внимания к объекту в эксперименте 1 быть результатом различных наборов задач в трех условиях внимания объекта, а не отражением механизмов внимания на основе объектов в зрительной коре головного мозга.
Участники
Все участники были здоровыми студентами-волонтерами из Калифорнийского университета в Дэвисе; имело нормальное зрение или зрение с поправкой на нормальное; дали информированное согласие; и получили зачетное время или денежную компенсацию за свое время.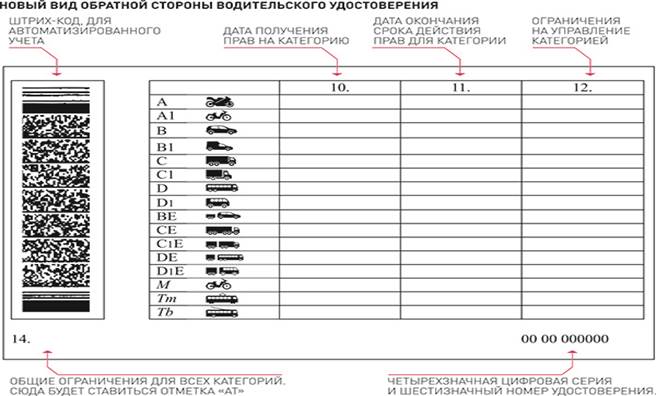 В эксперименте 1 данные ЭЭГ были записаны у 22 добровольцев (8 мужчин; 14 женщин). Двое добровольцев решили прекратить свое участие в середине эксперимента; данные оставшихся 20 участников (8 мужчин; 12 женщин) использовались для всех анализов.В эксперименте 2 данные ЭЭГ были записаны у 29 студентов; наборы данных от 4 участников были отклонены на основании непримиримого шума в данных или несоответствия субъекта, в результате чего был получен окончательный набор данных от 25 участников (9 мужчин; 16 женщин), который был использован для дальнейшего анализа декодирования. В эксперименте 3 данные ЭЭГ были записаны у 12 добровольцев (5 мужчин; 7 женщин). Наборы данных от двух участников были отклонены на основании непримиримого шума в данных ЭЭГ, в результате чего был получен окончательный набор данных ЭЭГ от 10 участников (5 мужчин и 5 женщин), который был использован для дальнейшего анализа декодирования.
В эксперименте 1 данные ЭЭГ были записаны у 22 добровольцев (8 мужчин; 14 женщин). Двое добровольцев решили прекратить свое участие в середине эксперимента; данные оставшихся 20 участников (8 мужчин; 12 женщин) использовались для всех анализов.В эксперименте 2 данные ЭЭГ были записаны у 29 студентов; наборы данных от 4 участников были отклонены на основании непримиримого шума в данных или несоответствия субъекта, в результате чего был получен окончательный набор данных от 25 участников (9 мужчин; 16 женщин), который был использован для дальнейшего анализа декодирования. В эксперименте 3 данные ЭЭГ были записаны у 12 добровольцев (5 мужчин; 7 женщин). Наборы данных от двух участников были отклонены на основании непримиримого шума в данных ЭЭГ, в результате чего был получен окончательный набор данных ЭЭГ от 10 участников (5 мужчин и 5 женщин), который был использован для дальнейшего анализа декодирования.
Дизайн эксперимента
В исследовании использовался дизайн внутри субъектов. В экспериментах 1 и 3 мы исследовали распределение альфа-мощности ЭЭГ на коже черепа в зависимости от категории обслуживаемых объектов в упреждающей задаче на внимание с тремя категориями объектов (лица, сцены и инструменты). В эксперименте 2 мы исследовали распределение мощности альфа-сигнала ЭЭГ на коже черепа во время послеоперационного периода, когда три категории объектов не были посещены заранее. Подробная информация о задаче на внимание, связанной с объектом, о задаче без привязки, и статистическом анализе представлены ниже.
В экспериментах 1 и 3 мы исследовали распределение альфа-мощности ЭЭГ на коже черепа в зависимости от категории обслуживаемых объектов в упреждающей задаче на внимание с тремя категориями объектов (лица, сцены и инструменты). В эксперименте 2 мы исследовали распределение мощности альфа-сигнала ЭЭГ на коже черепа во время послеоперационного периода, когда три категории объектов не были посещены заранее. Подробная информация о задаче на внимание, связанной с объектом, о задаче без привязки, и статистическом анализе представлены ниже.
Статистический анализ
Данные поведенческих реакций были проанализированы с помощью обобщенной линейной смешанной модели с гамма-распределением (Lo and Andrews, 2015) со случайным эффектом субъекта и фиксированными эффектами категории объекта и достоверности сигнала для количественной оценки эффекта достоверности сигнала по времени реакции (RT).
Различия в топографии альфа-мощности скальпа ЭЭГ в зависимости от состояния сигнала были проанализированы статистически с использованием подхода декодирования SVM и непараметрического кластерного теста перестановок и моделирования Монте-Карло. Статистический тест на основе кластера использовался для управления проблемами множественного сравнения, которые возникают, когда тесты t выполняются во все моменты времени в течение эпохи (Bae and Luck, 2018). Подробности статистического теста на альфа-мощность ЭЭГ описаны ниже.
Статистический тест на основе кластера использовался для управления проблемами множественного сравнения, которые возникают, когда тесты t выполняются во все моменты времени в течение эпохи (Bae and Luck, 2018). Подробности статистического теста на альфа-мощность ЭЭГ описаны ниже.
Эксперимент 1
Аппараты и раздражители.
Участники удобно расположились в электрически экранированном звукопоглощающем помещении (ETS-Lindgren). Стимулы предъявлялись на светодиодном мониторе VIEWPixx / EEG (модель VPX-VPX-2006A, VPixx Technologies) на расстоянии просмотра 85 см с центром по вертикали на уровне глаз.Диагональ дисплея составляла 23,6 дюйма, разрешение — 1920 × 1080 пикселей, частота обновления — 120 Гц. Комната для записи и предметы в ней были окрашены в черный цвет, чтобы избежать отраженного света, и она слабо освещалась лампами постоянного тока.
Каждое испытание начиналось с псевдослучайно выбранного представления одного из трех возможных типов сигналов в течение 200 мс (треугольник, квадрат или круг 1 ° × 1 °, с использованием PsychToolbox; Brainard, 1997; рис.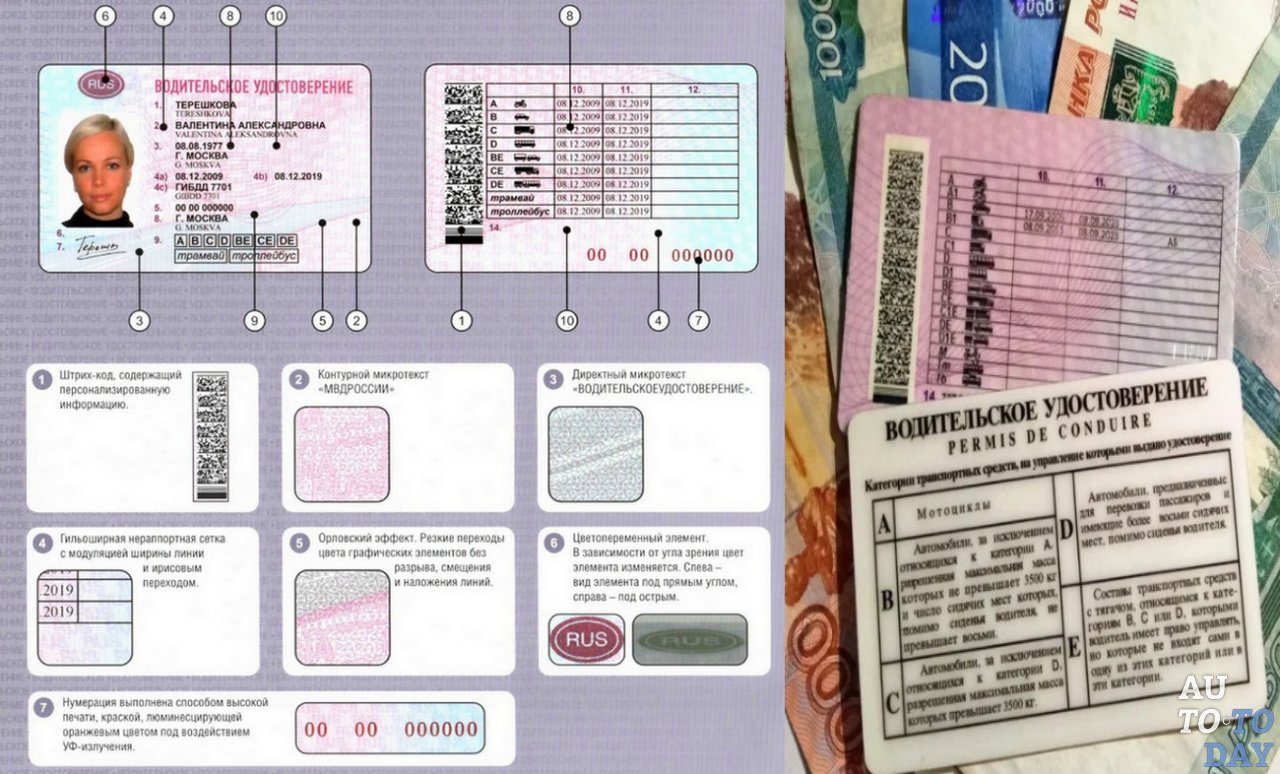 1 A ). Действительные сигналы информировали участников, какая категория целевых объектов (лицо, сцена или инструмент, соответственно), вероятно, появится впоследствии (вероятность 80%).Реплики располагались на 1 ° выше центральной точки фиксации. После псевдослучайно выбранных асинхронностей начала стимула (SOA; 1000–2500 мс) от начала сигнала, целевые стимулы (квадратное изображение 5 ° × 5 °) предъявлялись при фиксации в течение 100 мс. В случайных 20% испытаний реплики были недействительными, неправильно информируя участников о предстоящей категории целевых объектов. Для этих недействительных испытаний целевое изображение было отобрано с равной вероятностью из любой из двух категорий объектов без привязки. Все стимулы предъявлялись на сером фоне.Белая точка фиксации постоянно присутствовала в центре дисплея.
1 A ). Действительные сигналы информировали участников, какая категория целевых объектов (лицо, сцена или инструмент, соответственно), вероятно, появится впоследствии (вероятность 80%).Реплики располагались на 1 ° выше центральной точки фиксации. После псевдослучайно выбранных асинхронностей начала стимула (SOA; 1000–2500 мс) от начала сигнала, целевые стимулы (квадратное изображение 5 ° × 5 °) предъявлялись при фиксации в течение 100 мс. В случайных 20% испытаний реплики были недействительными, неправильно информируя участников о предстоящей категории целевых объектов. Для этих недействительных испытаний целевое изображение было отобрано с равной вероятностью из любой из двух категорий объектов без привязки. Все стимулы предъявлялись на сером фоне.Белая точка фиксации постоянно присутствовала в центре дисплея.
A , Пример пробной последовательности для задачи «Внимание». Каждое испытание начиналось с предъявления символической подсказки, которую испытуемые учили, предсказывали (80%) конкретную категорию объекта. После периода ожидания (от метки к цели), изменяющегося от 1,0 до 2,5 с, было представлено изображение объекта (лица, сцены или инструмента). В 20% испытаний было представлено одно из двух изображений цели без привязки.Испытуемые должны были быстро и точно различать аспекты изображений как в ожидаемых, так и в неожиданных условиях (подробности см. В тексте). B , Примеры целевых изображений, представленных в задаче на внимание. Изображения лиц, сцен и инструментов были выбраны из онлайн-баз данных.
После периода ожидания (от метки к цели), изменяющегося от 1,0 до 2,5 с, было представлено изображение объекта (лица, сцены или инструмента). В 20% испытаний было представлено одно из двух изображений цели без привязки.Испытуемые должны были быстро и точно различать аспекты изображений как в ожидаемых, так и в неожиданных условиях (подробности см. В тексте). B , Примеры целевых изображений, представленных в задаче на внимание. Изображения лиц, сцен и инструментов были выбраны из онлайн-баз данных.
Целевые изображения (Рис. 1 B ) были выбраны из 60 возможных изображений для каждой категории объектов. Все целевые изображения были собраны из Интернета. Изображения лица были фронтальными, с нейтральным выражением, лицами белой национальности, обрезанными и помещенными на белом фоне (Righi et al., 2012). Полнокадровые изображения сцены были взяты из коллекции естественных сцен Техасского университета в Остине (Geisler and Perry, 2011) и коллекции сцены кампуса (Burge and Geisler, 2011). Обрезанные изображения инструментов, размещенные на белом фоне, были взяты из Банка стандартизированных стимулов (Brodeur et al., 2014). Псевдослучайно распределенный интервал между испытаниями (ITI; 1500–2500 мс) отделял целевое смещение от начала сигнала следующего испытания. Каждый набор из 60 изображений объектов включал 30 изображений следующих различных подкатегорий: мужские / женские лица, городские / природные сцены и инструменты с питанием / без питания.
Обрезанные изображения инструментов, размещенные на белом фоне, были взяты из Банка стандартизированных стимулов (Brodeur et al., 2014). Псевдослучайно распределенный интервал между испытаниями (ITI; 1500–2500 мс) отделял целевое смещение от начала сигнала следующего испытания. Каждый набор из 60 изображений объектов включал 30 изображений следующих различных подкатегорий: мужские / женские лица, городские / природные сцены и инструменты с питанием / без питания.
Запись ЭЭГ.
Необработанные данные ЭЭГ были получены с помощью 64-канальной системы активных электродов Brain Products actiCAP (Brain Products) и оцифрованы с помощью входной платы и усилителя Neuroscan SynAmps2 (Compumedics). Сигналы регистрировались с помощью программного обеспечения для сбора данных Scan 4.5 (Compumedics) с частотой дискретизации 1000 Гц и полосой пропускания от постоянного тока до 200 Гц. Шестьдесят четыре активных электрода Ag / AgCl помещали в подогнанные эластичные колпачки, используя следующий монтаж в соответствии с международной системой 10–10 (Jurcak et al. , 2007): FP1, FP2, AF7, AF3, AFz, AF4, AF8, F7, F5, F3, F1, Fz, F2, F4, F6, F8, FT9, FT7, FC5, FC3, FC1, FCz, FC2, FC4, FC6, FT8, FT10, T7, C5, C3, C1, Cz, C2, C4, C6, T8, TP9, TP7, CP5, CP3, CP1, CPz, CP2, CP4, CP6, TP8, TP10, P7, P5, P3, P1, Pz, P2, P4, P6, P8, PO7, PO3, POz, PO4, PO8, PO9, O1, Oz, O 2 и PO10; с каналами AFz и FCz, назначенными как наземный и оперативный, соответственно. Кроме того, электроды в точках TP9 и TP10 были размещены непосредственно на левом и правом сосцевидных отростках.Электрод Cz был ориентирован на макушку головы каждого участника путем измерения спереди назад от назиона до иона и справа налево между преаурикулярными точками. Гель-электролит с высокой вязкостью наносили на каждый участок электрода для облегчения проводимости между электродом и кожей головы, а значения импеданса поддерживались на уровне <25 кОм. Непрерывные данные сохранялись в отдельных файлах, соответствующих каждому пробному блоку парадигмы стимула.
, 2007): FP1, FP2, AF7, AF3, AFz, AF4, AF8, F7, F5, F3, F1, Fz, F2, F4, F6, F8, FT9, FT7, FC5, FC3, FC1, FCz, FC2, FC4, FC6, FT8, FT10, T7, C5, C3, C1, Cz, C2, C4, C6, T8, TP9, TP7, CP5, CP3, CP1, CPz, CP2, CP4, CP6, TP8, TP10, P7, P5, P3, P1, Pz, P2, P4, P6, P8, PO7, PO3, POz, PO4, PO8, PO9, O1, Oz, O 2 и PO10; с каналами AFz и FCz, назначенными как наземный и оперативный, соответственно. Кроме того, электроды в точках TP9 и TP10 были размещены непосредственно на левом и правом сосцевидных отростках.Электрод Cz был ориентирован на макушку головы каждого участника путем измерения спереди назад от назиона до иона и справа налево между преаурикулярными точками. Гель-электролит с высокой вязкостью наносили на каждый участок электрода для облегчения проводимости между электродом и кожей головы, а значения импеданса поддерживались на уровне <25 кОм. Непрерывные данные сохранялись в отдельных файлах, соответствующих каждому пробному блоку парадигмы стимула.
Предварительная обработка ЭЭГ.
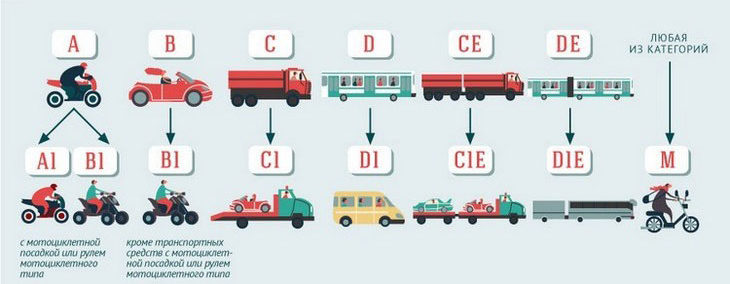
Все процедуры предварительной обработки данных были выполнены с помощью набора инструментов EEGLAB MATLAB (Delorme and Makeig, 2004).Для каждого участника все файлы данных ЭЭГ были объединены в единый набор данных перед обработкой данных. Каждый набор данных был визуально проверен на наличие плохих каналов, но таких каналов не наблюдалось. Данные были отфильтрованы с помощью окна Хэмминга sinc FIR (конечная импульсная характеристика) (1–83 Гц), а затем субдискретизированы до 250 Гц. Данные были алгебраически привязаны к среднему значению для всех электродов, а затем были отфильтрованы нижние частоты до 40 Гц. Данные были привязаны к интервалу от 500 мс до начала сигнала до 1000 мс после начала сигнала, так что ожидаемые данные всех испытаний можно было изучить вместе.Данные были визуально проверены, чтобы отметить и отклонить испытания с помощью морганий и движений глаз, которые произошли во время подачи сигнала. Затем было использовано разложение независимого компонентного анализа для удаления артефактов, связанных с морганиями и движениями глаз.
Анализ ЭЭГ.
Мы использовали процедуру спектральной плотности мощности с функцией периодограммы Matlab (x) (длина окна, 500 мс; длина шага, 40 мс), чтобы извлечь мощность в альфа-диапазоне для каждого электрода, а также для каждого участника и сигнала. условие.Мощность в альфа-диапазоне рассчитывалась как среднее значение мощности от 8 до 12 Гц. Для каждого участника и условия сигнала результаты спектральной плотности мощности рассчитывались в отдельных испытаниях, а затем усреднялись по испытаниям. Усредненные результаты спектральной плотности мощности использовались для визуального изучения топографии мощности альфа-диапазона в различных условиях сигнала.
Мы реализовали анализ декодирования, чтобы количественно оценить, было ли внимание объекта систематически связано с изменениями фазонезависимой топографии мощности альфа-диапазона в зависимости от условий.Эта процедура анализа была адаптирована из процедуры декодирования представлений рабочей памяти из ЭЭГ кожи головы (Bae and Luck, 2018).
Декодирование выполнялось независимо в каждый момент времени в пределах эпох. Мы реализовали нашу модель декодирования с помощью функции Matlab fitecoc (x) , чтобы использовать комбинацию SVM и алгоритмов кодирования вывода с исправлением ошибок (ECOC). Отдельный бинарный классификатор был обучен для каждого условия сигнала, используя подход «один против одного», с объединением производительности классификатора в рамках подхода ECOC.Таким образом, декодирование считалось правильным, когда классификатор правильно определил условие реплики из трех возможных условий реплики, а вероятность выполнения была установлена на уровне 33,33% (одна треть).
Декодирование для каждого момента времени следовало шестикратной процедуре перекрестной проверки. Данные пяти шестых испытаний, выбранных случайным образом, были использованы для обучения классификатора правильной маркировке. Оставшаяся одна шестая испытаний была использована для тестирования классификатора с помощью функции Matlab pred (x) . Вся процедура обучения и тестирования повторялась 10 раз, при этом новые данные для обучения и тестирования назначались случайным образом на каждой итерации. Для каждого условия сигнала, каждого участника и каждой временной точки точность декодирования вычислялась путем суммирования количества правильных маркировок в испытаниях и итерациях и деления на общее количество маркировок.
Мы усреднили вместе результаты декодирования для всех 10 итераций, чтобы проверить точность декодирования для всех участников в каждый момент времени в эпоху.В любой момент времени высокая точность декодирования предполагает, что альфа-топография содержит информацию о категории обслуживаемых объектов. Однако сравнения точности декодирования со случайностью самого по себе недостаточно для оценки того, является ли вывод, сделанный на основе точности декодирования, надежным. Несмотря на то, что односторонний тест t для определения точности декодирования разных испытуемых против случайности даст значение t и результат статистической значимости для рассматриваемой временной точки, проведя тот же тест в каждой из 375 временных точек, включенных в нашу эпоху.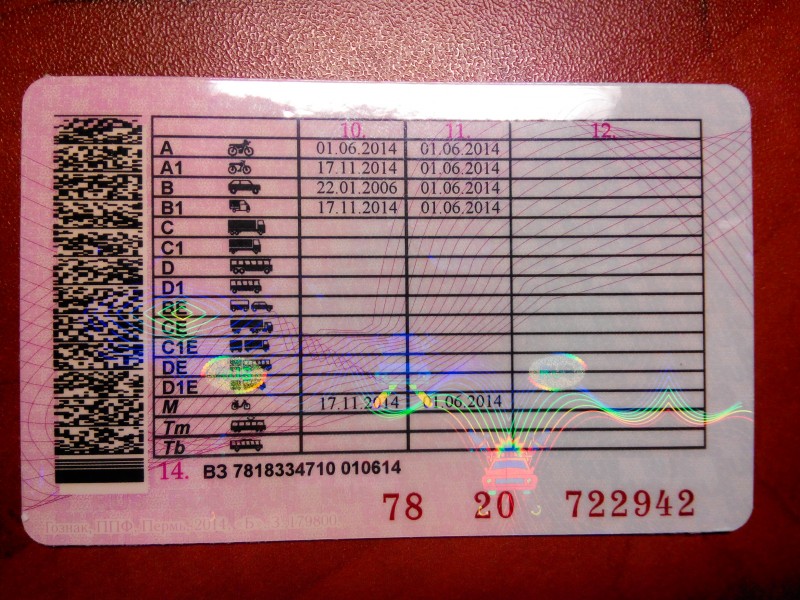 потребует поправки на множественные поправки, что приведет к чрезмерно консервативным статистическим тестам.Поэтому, следуя исследованию Bae and Luck (2018), мы использовали оценку значимости на основе моделирования методом Монте-Карло, чтобы выявить статистически значимые кластеры точности декодирования.
потребует поправки на множественные поправки, что приведет к чрезмерно консервативным статистическим тестам.Поэтому, следуя исследованию Bae and Luck (2018), мы использовали оценку значимости на основе моделирования методом Монте-Карло, чтобы выявить статистически значимые кластеры точности декодирования.
С помощью статистического метода Монте-Карло точность декодирования оценивалась по случайно выбранному целому числу (1, 2 или 3), представляющему экспериментальные условия, для каждой временной точки. Тест t точности классификации участников против случайности проводился в каждый момент времени для перемешанных данных.Были идентифицированы кластеры последовательных моментов времени, точность декодирования которых была определена как статистически значимая с помощью теста t , и масса кластера t была рассчитана для каждого кластера путем суммирования значений t , заданных каждым составляющим тестом t . Каждый кластер сэкономил т массы .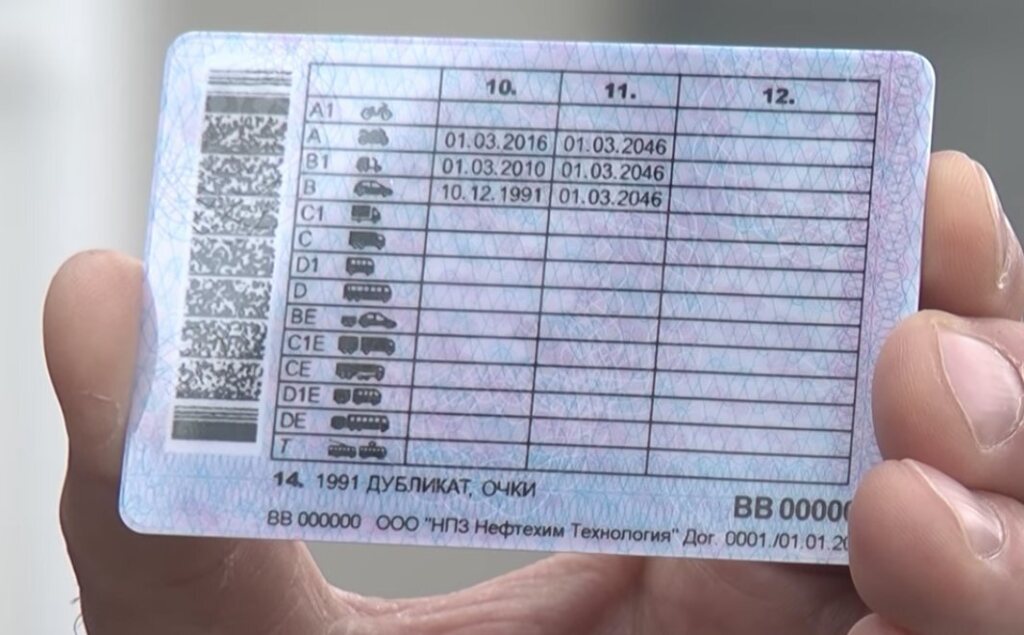 Эта процедура была повторена 1000 раз для генерации распределения масс t для представления нулевой гипотезы о том, что данный кластер масс t из нашего анализа декодирования, вероятно, был найден случайно.95% -ное пороговое значение массы t было определено из нулевого распределения на основе перестановок и использовано в качестве порогового значения, с которым можно сравнивать массы кластера t , вычисленные на основе наших исходных данных декодирования. Кластеры последовательных моментов времени в исходных результатах декодирования с массами ± , превышающими порог, основанный на перестановках, считались статистически значимыми.
Эта процедура была повторена 1000 раз для генерации распределения масс t для представления нулевой гипотезы о том, что данный кластер масс t из нашего анализа декодирования, вероятно, был найден случайно.95% -ное пороговое значение массы t было определено из нулевого распределения на основе перестановок и использовано в качестве порогового значения, с которым можно сравнивать массы кластера t , вычисленные на основе наших исходных данных декодирования. Кластеры последовательных моментов времени в исходных результатах декодирования с массами ± , превышающими порог, основанный на перестановках, считались статистически значимыми.
Мы выполнили ту же процедуру декодирования фазонезависимой колебательной активности ЭЭГ в тета-диапазоне (4–7 Гц), бета-диапазоне (16–31 Гц) и гамма-диапазоне (32–40 Гц), чтобы проверить гипотезу, что объект Модуляции активности ЭЭГ, основанные на внимании, специфичны для альфа-диапазона.Для фильтрации данных ЭЭГ в бета- и гамма-диапазоны мы установили минимальный порядок фильтрации, равный трехкратному количеству отсчетов в экспериментальную эпоху. Для фильтрации по тета-диапазону мы установили минимальный порядок фильтрации, равный двукратному количеству отсчетов, потому что длительность эпохи не была достаточно большой, чтобы позволить порядок фильтрации в три раза больше количества отсчетов.
Для фильтрации по тета-диапазону мы установили минимальный порядок фильтрации, равный двукратному количеству отсчетов, потому что длительность эпохи не была достаточно большой, чтобы позволить порядок фильтрации в три раза больше количества отсчетов.
Порядок действий.
Участники были проинструктированы сохранять фиксацию в центре экрана во время каждого испытания и предвосхищать категорию объекта с указанием, пока не появится целевое изображение.Кроме того, им было поручено указать подкатегорию объекта целевого изображения (например, мужчина / женщина) нажатием кнопки как можно быстрее и точнее в целевой презентации, используя кнопку указательного пальца для мужчин (лицо), природы (сцена) и питания. (инструмент) и нажмите кнопку среднего пальца для женщин (лицо), городских (сцена) и без питания (инструмент). Ответы регистрировались только во время ITI между целевым началом и следующим испытанием. Испытания были классифицированы как правильные, когда записанный ответ соответствовал подкатегории целевого изображения, и неправильный, когда ответ не совпадал или когда не было записанного ответа. Каждый блок экспериментов включал 42 испытания продолжительностью ~ 3 мин. Каждый участник выполнил 10 блоков эксперимента.
Эксперимент 2
Протоколы записи и анализа были идентичны протоколам эксперимента 1. Учитывая, что цель этого эксперимента состояла в том, чтобы проверить, могла ли точность декодирования в подготовительном периоде между началом сигнала и целевым началом быть основана на различиях Что касается сенсорных процессов, вызываемых в зрительной системе различными сигнальными стимулами, мы модифицировали эксперимент 1, сделав реплики непредсказуемыми для предстоящей целевой категории.В соответствии с этой модификацией мы проинструктировали участников, что форма реплики неинформативна, и что представление реплики было просто для предупреждения их о том, что целевой стимул скоро появится. Участников не проинструктировали игнорировать форму реплики. Хотя временной ход различий в сенсорных ответах в ЭЭГ кожи головы, отфильтрованных до частот альфа-диапазона, трудно измерить, на основе предыдущей литературы (Bae and Luck, 2018) мы предсказали, что даже для альфы любой дифференцируемый вызванный стимулом сенсорная активность будет ограничена временным окном в пределах 200 мс после начала сигнала. Каждый участник выполнил 10 блоков эксперимента, в каждом блоке по 42 попытки.
Каждый участник выполнил 10 блоков эксперимента, в каждом блоке по 42 попытки.
Эксперимент 3
Протоколы записи и анализа были идентичны протоколам эксперимента 1. Целью этого эксперимента было выяснить, могли ли различия в альфа-топографии в разных условиях внимания объекта в эксперименте 1 быть результатом различных наборов задач в разных группах. три состояния объектного внимания, а не отражающие объектно-ориентированные механизмы внимания в зрительной коре.В частности, в условиях присутствия лица в эксперименте 1 участников проинструктировали различать, было ли представленное лицо мужским или женским, и указывать свой выбор, используя поле кнопок с двумя кнопками под указательным и средним пальцами. В условии присутствия на сцене задача заключалась в том, чтобы отличить городские сцены от естественных с помощью тех же двух кнопок, а в условиях использования инструментов присутствия задача заключалась в том, чтобы отличить питание от инструментов без источника питания с помощью тех же двух кнопок. Поскольку различаемые категории были разными в разных условиях (мужской / женский, городской / естественный, электроинструмент / ручной инструмент), возможно, что участники готовили разные наборы задач в разных условиях реплики в течение подготовительного периода.Например, после представления треугольной реплики участнику потребуется когнитивно сопоставить реакцию своего указательного пальца на идентификацию мужского лица и реакцию среднего пальца на идентификацию женского лица, тогда как это сопоставление будет другим, если Участнику был вручен квадратный кий. Эти различные наборы задач и сопоставления от зрительной коры головного мозга к подготовке двигательной реакции могли, возможно, управлять различными альфа-топографиями кожи головы в течение подготовительного периода.
Поскольку различаемые категории были разными в разных условиях (мужской / женский, городской / естественный, электроинструмент / ручной инструмент), возможно, что участники готовили разные наборы задач в разных условиях реплики в течение подготовительного периода.Например, после представления треугольной реплики участнику потребуется когнитивно сопоставить реакцию своего указательного пальца на идентификацию мужского лица и реакцию среднего пальца на идентификацию женского лица, тогда как это сопоставление будет другим, если Участнику был вручен квадратный кий. Эти различные наборы задач и сопоставления от зрительной коры головного мозга к подготовке двигательной реакции могли, возможно, управлять различными альфа-топографиями кожи головы в течение подготовительного периода.
Это объяснение не является взаимоисключающим с нашей интерпретацией, согласно которой альфа-топографии кожи головы отражают различное подготовительное смещение внимания в визуальных областях, отобранных по категориям объектов, но, учитывая план эксперимента 1, нет способа узнать, одно, другое или оба отражены в различных альфа-паттернах. Поэтому мы провели эксперимент, который приравнял задачу ко всем условиям внимания к объекту, чтобы устранить любые различия в наборе задач, которые присутствовали в исходном эксперименте.Основываясь на нашей модели, согласно которой альфа — это механизм избирательного внимания к объектам в зрительной коре, в этом новом дизайне мы все еще должны наблюдать различные паттерны альфа-сигналов для подготовительного внимания к категориям объектов, которые должны быть обнаружены при успешном декодировании на поздних этапах пути к целевому периоду.
Поэтому мы провели эксперимент, который приравнял задачу ко всем условиям внимания к объекту, чтобы устранить любые различия в наборе задач, которые присутствовали в исходном эксперименте.Основываясь на нашей модели, согласно которой альфа — это механизм избирательного внимания к объектам в зрительной коре, в этом новом дизайне мы все еще должны наблюдать различные паттерны альфа-сигналов для подготовительного внимания к категориям объектов, которые должны быть обнаружены при успешном декодировании на поздних этапах пути к целевому периоду.
Аппараты и раздражители.
Общая структура парадигмы для эксперимента 3 следовала парадигме эксперимента 1. В каждом испытании появлялась форма реплики, указывающая категорию объекта для участия.Формы реплик были идентичны таковым в эксперименте 1. Как и раньше, за репликой следовал подготовительный период, а затем появлялось изображение стимула. ITI разделил изображение стимула и начало следующего испытания. Во время этого ITI собирались поведенческие ответы. Диапазоны SOA и ITI оставались такими же, как в эксперименте 1.
Диапазоны SOA и ITI оставались такими же, как в эксперименте 1.
Поведенческая задача для этого эксперимента заключалась в том, чтобы определить, в каждом испытании, было ли кратко представленное целевое изображение, принадлежащее к категории объектов с указанием (лица, сцены или инструменты) в фокусе или размыто.В отличие от экспериментов 1 и 2, стимулы, подлежащие различению, представляли собой составные части изображения, принадлежащего целевой категории, наложенного на изображение, принадлежащее к категории отвлекающих факторов. Важно отметить, что и целевое изображение, и изображение-отвлекающий элемент в смеси могут быть в фокусе или размытыми независимо друг от друга; следовательно, задача не могла быть выполнена исключительно на основе внимания и реакции на присутствие или отсутствие размытия (например, см. Результаты эксперимента 3).
Двадцать процентов испытаний были неверно запрошены, что позволяет нам оценить влияние достоверности реплики на поведенческие характеристики.Для недействительных испытаний изображение стимула представляло собой композицию изображения из случайно выбранной категории объектов без привязки, наложенного на черно-белую шахматную доску. Шахматная доска также может быть размытой или в фокусе независимо от изображения объекта. Участников проинструктировали, что всякий раз, когда они сталкивались с испытанием, в котором смешанный стимул не включал изображение, принадлежащее к категории объекта с указанием, а вместо этого содержал только одно изображение объекта и наложение шахматной доски, они должны были указать, является ли изображение объекта без привязки в стимуле был расплывчатым или в фокусе.Мы предсказали, что участники будут медленнее реагировать на испытания с неверными указаниями, что аналогично поведенческому эффекту достоверности, наблюдаемому в парадигмах пространственного внимания с указанием указаний.
Изображения стимула охватывали квадрат 5 ° × 5 ° угла обзора. Для создания размытых изображений к изображениям применялось размытие по Гауссу со значением SD 2.
Все три категории объектов включали 40 различных индивидуальных изображений. В каждом испытании были нарисованы случайные изображения для создания составного изображения стимула. Изображения сцен и инструментов были взяты из тех же наборов изображений, что и для исходного эксперимента.Однако изображения лиц были взяты из другого набора изображений (Ma et al., 2015), потому что изображения лиц, использованные в исходном эксперименте, не имели достаточно высокого разрешения, чтобы обеспечить достоверно заметные различия в размытых и не размытых условиях. Все изображения лиц были обрезаны до овалов с центром на лице и помещены на белом фоне.
В отличие от изображений сцены, которые содержат визуальные детали, охватывающие весь квадрат 5 ° × 5 °, изображения лиц и инструментов были установлены на белом фоне и поэтому не содержали визуальной информации до всех границ изображения.Следовательно, чтобы исключить возможность того, что участники могут использовать информацию о сигнале для фокусировки пространственного внимания вместо объектно-ориентированного внимания для выполнения размытого / сфокусированного различения в любом испытании, в котором изображение лица или инструмента было включено в составной стимул, положение этого изображение лица или инструмента было случайным образом смещено из центра.
Порядок действий.
Участники были проинструктированы как можно быстрее реагировать на целевой стимул, поэтому очень важно, чтобы участники занимались подготовительным вниманием к категории объектов с указанием в течение подготовительного периода.Все участники были обучены по крайней мере 126 попыткам выполнения задания и смогли достичь не менее 60% точности ответа перед выполнением его в рамках сбора данных ЭЭГ; для этого продолжительность стимула была скорректирована для каждого участника на начальном этапе обучения. Эксперимент 3 был проведен в той же лабораторной среде, что и исходный эксперимент, и переменные настройки окружающей среды были приравнены к параметрам исходного эксперимента.
Каждый участник выполнил 15 блоков эксперимента, каждый из которых включал 42 испытания, что в среднем представляло на 210 испытаний на одного субъекта больше, чем эксперимент 1.
Результаты
Эксперимент 1
Поведенческие результаты
Наблюдаемая точность ответа была высокой и одинаковой для всех условий объекта и условий действительности (недопустимое лицо 96,6%; недопустимая сцена 97,1%; допустимое лицо 96,8%; допустимая сцена 96,7 %; действительный инструмент, 93,1%), за исключением недопустимого условия обслуживания (87,5%), которое мы рассмотрим ниже.
Чтобы определить, вызвала ли наша задача поведенческий эффект внимания, мы сравнили RT для определения целевых различий между испытаниями с действительной и недействительной подсказкой.Мы наблюдали более быстрые средние RT для действительных испытаний, чем для недействительных испытаний, усредняясь по условиям (рис. 2 A ) и для каждого условия отдельно (рис. 2 B ).
Рисунок 2.Поведенческие меры внимания в эксперименте 1. A , Ящичковые диаграммы данных о времени реакции для недействительных и достоверных испытаний для 20 субъектов, усредненные по состояниям внимания (объекта). Толстые горизонтальные линии внутри прямоугольников представляют собой медианные значения. Первый и третий квартили показаны как нижний и верхний края прямоугольника.Вертикальные линии проходят до самых крайних точек данных, за исключением выбросов. Точки над графиками представляют выбросы, которые были определены как любое значение, превышающее третий квартиль плюс 1,5-кратный межквартильный размах. Субъекты в целом были значительно быстрее для объектов с указанием (действительных), чем с объектами с указанием (недопустимые). B , Время реакции для действительных и недействительных испытаний отдельно для каждого состояния внимания. Субъекты были значительно быстрее для объектов с указанием (действительных), чем для объектов с указанием (недопустимых) для каждой категории объектов.
Чтобы количественно оценить влияние достоверности реплики на RT, мы подобрали обобщенную линейную смешанную модель с гамма-распределением к данным RT (Lo and Andrews, 2015). Мы обнаружили значительный эффект валидности (действительный или недействительный, p <0,001). Модель также выявила значительный главный эффект категории объекта ( p <0,001) из-за более медленного общего времени реакции в категории инструмента. Таким образом, испытуемые были менее точны и медленнее реагировали на категорию инструментов.Несмотря на эти незначительные снижения производительности для категории инструментов, тем не менее наблюдался значительный поведенческий эффект внимания для категории инструментов, что свидетельствует о том, что испытуемые использовали все три типа сигналов, чтобы подготовиться к различению и реагированию на приближающиеся объекты.
Результаты альфа-топографии. но до появления целевых раздражителей.Чтобы выделить различия между альфа-топографиями между условиями и контролировать неспецифические эффекты поведенческого возбуждения, мы создали попарные карты различий альфа-топографии одного состояния внимания объекта, вычтенного из другого состояния внимания объекта.
Мы наблюдали, что различия в альфа-топографии между условиями объекта возникали и развивались в течение периода упреждения (от сигнала к цели) (рис. 3). В топографиях посещаемости без присутствия (рис.3 A ), мы наблюдали повышенную альфа-мощность над левой задней частью скальпа и уменьшенную альфа-мощность над правой задней частью скальпа в течение периода упреждения, при этом латерализация становилась наиболее заметной при более длительных послеоперационных латентных периодах. В топографиях «лицо минус инструмент» (рис. 3 B ) картина была аналогичной в самые длинные латентные периоды, но была более изменчивой в промежуточные периоды времени. В топографиях посещаемости минус посещаемость (рис. 3 C ), паттерн альфа-различий отличался от тех, которые связаны с условиями присутствия; при самых длительных послеоперационных латентных периодах картина силы альфа-излучения на коже черепа была обратной, чем на других картах разницы, причем сила альфа-излучения была выше слева, чем на правой задней части скальпа.В целом наличие этих различий между состояниями согласуется с вариациями основных паттернов корковой альфа-мощности во время упреждающего внимания к лицам, сценам и инструментам. Однако, учитывая вариабельность между субъектами и присущую им сложность количественной оценки карт различий между субъектами в зависимости от состояния внимания, мы обратились к методу декодирования ЭЭГ, чтобы количественно оценить различия в мощности альфа в условиях, которые качественно описаны выше.
Рис. 3.Карты топографических различий для мощности альфа в эксперименте 1. A , Карты различий для упреждающего внимания к лицам без сцен. График разности альфа-топографии для условий присутствия минус условия присутствия, усредненного по участникам для четырех временных окон относительно начала сигнала. Карты топографических различий отображаются только до 1000 мс после начала сигнала, когда могут появиться самые короткие целевые значения задержки. Вид на эти разностные карты из-за головы.См. Описание в тексте. B , Карты различий для упреждающего внимания к лицам без инструментов. График разности альфа-топографии для условий посещаемости минус условия посещаемости, усредненные по участникам. C , Карты различий для упреждающего внимания к инструментам без сцен. График разности альфа-топографии для условий посещаемости минус условия присутствия, усредненные по участникам.
Результаты декодирования SVM
Результаты декодирования SVM (рис.4) выявил статистически значимую точность декодирования в двух кластерах временных точек в диапазоне 500–800 мс после спасения и перед целью (рис. 4, бирюзовые точки). Точность декодирования в диапазоне от -100 до +200 мс в начале сигнала не достигла порога статистической значимости.
Рисунок 4.Точность декодирования альфа-диапазона в эксперименте 1. Точность декодирования активности альфа-диапазона в течение эпохи для разных участников. Горизонтальная красная линия представляет собой случайную точность декодирования.Сплошная изменяющаяся во времени линия представляет собой среднюю точность декодирования по каждому объекту в каждый момент времени, а заштрихованная область вокруг этой линии — это SEM. Серая заливка обозначает период предварительного ожидания, а сегмент с оранжевой заливкой представляет период ожидания между началом сигнала (0 мс) и самым ранним достижением цели (1000 мс). Бирюзовые точки обозначают моменты времени, которые принадлежат статистически значимым кластерам точности декодирования, как определено оценкой Монте-Карло.
Результаты SVM-декодирования осцилляторной активности ЭЭГ в тета-, бета- и гамма-диапазонах не выявили статистически значимого декодирования в период упреждения (рис.5).
Рисунок 5.Декодирование для разных частотных диапазонов ЭЭГ в эксперименте 1. A , Та же процедура декодирования SVM и статистическая процедура Монте-Карло, которые использовались для анализа данных альфа-диапазона, были применены к тета-диапазону (4– 7 Гц). B , Тот же конвейер декодирования был применен к бета-диапазону (16–31 Гц), что не выявило статистически значимых кластеров с высокой точностью декодирования в подготовительный период. C , Тот же конвейер декодирования также был применен к гамма-диапазону (32–40 Гц) и, аналогичным образом, не выявил статистически значимых кластеров с высокой точностью декодирования в подготовительный период.
Эксперимент 2
Мы наблюдали статистически значимый кластер моментов времени с исключительной точностью декодирования только в окне представления сигнала. Никаких дальнейших кластеров декодирования со значительно большей вероятностью не происходило где-либо в интервале от 200 до 1000 мс (рис. 6).
Рисунок 6.Точность декодирования альфа-диапазона для эксперимента 2. Та же процедура декодирования SVM и статистическая процедура Монте-Карло, которые использовались для анализа данных из эксперимента 1, были применены к альфа-диапазонной ЭЭГ из эксперимента 2, выявив кластер статистически важные моменты времени, близкие к началу сигнала, но не позднее подготовительного периода.
Результаты этого контрольного эксперимента опровергают возможность того, что декодирование позднего периода альфа-диапазона, которое мы наблюдали в нашем первоначальном эксперименте, было просто результатом дифференциальных восходящих сенсорных процессов в трех условиях сигнала. Поскольку парадигма эксперимента 2 была идентична парадигме эксперимента 1 во всех отношениях, кроме достоверности реплики, и потому что мы использовали тот же конвейер декодирования SVM для данных ЭЭГ в альфа-диапазоне из эксперимента 2, как и в эксперименте 1, мы могли напрямую оценить, была ли схема результатов декодирования, полученных нами в первоначальном эксперименте, связана с восходящими сенсорными процессами.
Для эксперимента 2 мы собрали данные от большего числа участников, чем для нашего первоначального эксперимента, чтобы у нас было больше возможностей для оценки величины и временной степени декодирования, которое могло быть достигнуто исключительно на основе вызванной стимулом активности. Наши результаты подтверждают идею о том, что сверх-случайное декодирование с большой задержкой в эксперименте 1 не связано с чисто сенсорной активностью, обусловленной различиями физических стимулов, потому что мы обнаружили, что в эксперименте 2 статистически значимое сверх-случайное декодирование происходило только в кластере времени. указывает на короткую задержку после спасения (<200 мс после начала сигнала; рис.6).
Эксперимент 3
Поведенческие результаты
В задаче различения размытых и сфокусированных изображений (рис.7) мы наблюдали различия в RT между действительными и недействительными испытаниями для всех категорий объектов, так что испытания с достоверными указаниями вызывали более быстрые ответы, чем неправильно назначенные испытания (рис. 8). При подгонке обобщенной линейной смешанной модели с гамма-распределением к данным RT мы обнаружили значительный эффект достоверности ( p <0,001).
Рис. 7.Пример изображения цели в задаче на внимание для эксперимента 3.В этом наборе примеров лицо — это категория целевого объекта, которая будет идентифицирована как находящаяся в фокусе или размытая, а наложенные изображения инструмента или сцены являются изображениями-отвлекающими элементами. Для каждого стимульного изображения и цель, и отвлекающий фактор могут быть размытыми или в фокусе независимо друг от друга.
Рисунок 8.Поведенческие меры внимания в эксперименте 3. A , Ящичковые диаграммы данных о времени реакции для недействительных и достоверных испытаний для 12 субъектов, усредненных по состояниям внимания (объекта).Толстые горизонтальные линии внутри прямоугольников представляют собой медианные значения. Первый и третий квартили показаны как нижний и верхний края прямоугольника. Вертикальные линии проходят до самых крайних точек данных, за исключением выбросов. Точки над графиками представляют выбросы, определяемые как любое значение, превышающее третий квартиль плюс 1,5 межквартильного размаха. Субъекты в целом были значительно быстрее для объектов с указанием (действительных), чем с объектами с указанием (недопустимые). B , Время реакции для действительных и недействительных испытаний отдельно для каждого состояния внимания.Субъекты были значительно быстрее для объектов с указанием (действительных), чем для объектов с указанием (недопустимых) для каждой категории объектов.
Результаты декодирования SVM
Используя тот же анализ ЭЭГ и конвейер декодирования SVM, что и в эксперименте 1, мы обнаружили статистически значимые кластеры временных точек, демонстрирующих точность декодирования выше шансов (рис. 9). Как и в эксперименте 1, эти статистически значимые кластеры наблюдались во второй половине подготовительного периода,> 500 мс после начала реплики.Примечательно, что в окне представления сигнала 0–200 мс также, по-видимому, есть группа моментов времени с высокой вероятностью, в тот же период, когда мы наблюдали статистически значимое декодирование в эксперименте 2, которое было связано с сенсорной активностью, вызванной сигналом. Однако в результатах эксперимента 3, как и в эксперименте 1, декодирование в этот период времени предъявления сигнала (задержка <200 мс) не достигло уровня статистической значимости (тогда как при большем количестве участников в эксперименте 2 это могло быть выявлено. ).
Рисунок 9.Точность декодирования альфа-диапазона для эксперимента 3. Та же процедура декодирования SVM и статистическая процедура Монте-Карло, которые использовались для анализа данных из эксперимента 1, были применены к альфа-диапазону ЭЭГ из эксперимента 3, выявив кластер статистически знаменательные моменты времени во второй половине подготовительного периода.
Поведенческие результаты эксперимента 3 предполагают, что участники привлекали объектно-ориентированное внимание в течение подготовительного периода. Участники быстрее распознали изображения объектов как размытые или сфокусированные, когда их категория получила указание.По аналогии с парадигмами пространственного внимания с указаниями, в испытаниях с недопустимыми указаниями участники обращались к одной категории объектов в течение подготовительного периода, но затем, при предъявлении стимула, переориентировали свое внимание, чтобы иметь возможность различать, было ли изображение из категории объектов без привязки размытым или размытым. фокус.
Поскольку поведенческий эффект между действительными и недействительными испытаниями соответствует таковому в нашем первоначальном эксперименте, мы уверены, что экспериментальный план в эксперименте 3 порождал ту же форму объектно-ориентированного внимания сверху вниз, что и было зафиксировано в эксперименте 1.Таким образом, при наблюдении статистически значимого сверхшансного декодирования в том же общем окне времени после появления сигнала для экспериментов 1 и 3 мы интерпретируем этот результат как доказательство того, что внимание, основанное на объекте, а не различия в постановке задачи или подготовке двигательной реакции, является движущей силой. результат декодирования с большей задержкой до наступления целей.
Обсуждение
Объектное внимание — фундаментальный компонент естественного зрения. Люди перемещаются по миру главным образом на основе взаимодействий с объектами, которые изобилуют в типичных средах (O’Craven et al., 1999; Scholl, 2001). Примат объектов означает, что адаптивное взаимодействие с миром требует представлений объектов высокого уровня, которые отличаются от визуальных характеристик низкого уровня в той же области пространства. Следовательно, воздействие внимания непосредственно на репрезентации объектов является критическим аспектом восприятия (Woodman et al., 2009). Было показано, что внимание действует на репрезентации объектов (Типпер и Берманн, 1996; Берманн и др., 1998), поэтому выявление нейронных механизмов, с помощью которых внимание влияет на репрезентации объектов, является ключевой задачей когнитивной нейробиологии.
Физиологические исследования показывают, что повышение эффективности внимания коррелирует с изменениями нейронной активности в системах восприятия. Корковые структуры, кодирующие сопровождаемую информацию, показывают повышенную амплитуду сигнала, синхронность и / или функциональную связность (Moore and Zirnsak, 2017). Как нервная система механистически контролирует эту корковую возбудимость и эффективность обработки, остается не совсем понятным, но большинство моделей предполагают, что нисходящие управляющие сигналы от сетей более высокого порядка в лобной и теменной коре изменяют обработку в сенсорных / перцептивных областях коры, кодирующих наблюдаемую и необслуживаемую информацию ( Петерсен и Познер, 2012).Одной из гипотез нейронной сигнатуры нисходящего контроля на уровне сенсорной / перцептивной коры является фокусная альфа-сила (Jensen and Mazaheri, 2010). Изменения в мощности альфа происходят во время пространственного внимания (Worden et al., 2000) и особого внимания (Snyder and Foxe, 2010). Здесь мы исследовали механизмы на основе альфа-канала, опосредующие избирательное внимание к объектам, привлекая внимание к различным объектам и измеряя изменения в записанной на коже головы альфа-мощности ЭЭГ. Мы объединили поведение с топографическим картированием и декодированием ЭЭГ, чтобы проверить гипотезу о том, что внимание к объекту включает селективные модуляции мощности альфа-излучения в объектно-специфической коре головного мозга.
Мы выбрали лица, сцены и инструменты в качестве объектов внимания, потому что было показано, что эти объекты активируют ограниченные области в зрительной коре. Веретенообразная область лица (FFA) избирательно реагирует на изображения вертикальных лиц (Allison et al., 1994; Kanwisher and Yovel, 2006): лица могут считаться объектами, потому что, например, данные пациентов с прозопагнозией предполагают, что аналогичные механизмы лежат в основе распознавания лиц и объектов (Gauthier et al., 1999).Площадь парагиппокампа (PPA) реагирует на сцены (Epstein et al., 1999) и, в частности, на категорию сцены (Henriksson et al., 2019). Области, чувствительные к инструментам, были идентифицированы в вентральном и дорсальном зрительных путях (Kersey et al., 2016). В соответствии с предсказанием, что объектно-ориентированное внимание модулирует альфа-канал в визуальных областях, специализированных для обработки категории обслуживаемых объектов, внимание к лицам должно выборочно снижать активность альфа-диапазона в визуальных областях с отбором по лицам, таких как FFA, внимание к сценам должно уменьшать альфа-диапазон активность в областях, отобранных для выбора места, таких как PPA, и внимание к инструментам должно снизить активность альфа-диапазона по выборочным областям вентральных и дорсальных зрительных путей.ЭЭГ не является сильным методом локализации нейронных источников мозговой активности, но, учитывая, что области FFA, PPA и постулируемые специализированные области инструментов расположены в разных областях коры головного мозга, закономерности альфа-модуляции с вниманием в этих областях можно было бы ожидать. для получения дифференциальных альфа-паттернов ЭЭГ на коже черепа. Учитывая, что можно ожидать, что такие паттерны будут отличаться лишь незначительно и трудно предсказать, одним из способов оценки различных паттернов альфа для внимания к различным объектам является включение машинного обучения для декодирования альфа-паттернов ЭЭГ кожи головы.Таких различий следует ожидать только в том случае, если фокусная модуляция альфа также участвует в избирательном внимании объекта.
Наши результаты времени реакции показали, что участники, которые привлекали объектно-ориентированное внимание к категориям объектов, на которые указывает указание, быстрее идентифицировали объекты с указанием. Теоретически, когда участники должны предвидеть конкретную категорию объектов, они будут искажать нейронную активность в областях коры, специализированных для этого типа объекта, и, возможно, также искажать активность в областях коры, обрабатывающих все визуальные особенности нижнего уровня, связанные с этим объектом (Коэн и Тонг, 2015).Когда цель появляется, ее визуальные свойства, таким образом, интегрируются, облегчая необходимое восприятие различения. Когда появляется объект из непредвиденной (необработанной) категории, активность в областях, отобранных для объекта, и связанных областях визуальных характеристик для объектов без привязки будет относительно подавлена, что задерживает интеграцию и семантический анализ несвязанных целевых изображений и замедляет время реакции.
Топографические карты альфа-различий менялись в зависимости от категории объекта, на котором присутствовали участники.Различная альфа-топография соответствовала паттернам ЭЭГ кожи головы, которых можно было бы ожидать, если бы альфа-модуляции происходили в разных основных корковых генераторах (корковых пятнах или областях) для трех категорий объектов. Множество доказательств лежащих в основе нейроанатомических субстратов лица, сцены и обработки инструментов из исследований изображений позволяет делать некоторые прогнозы относительно наших данных в отношении предполагаемой природы фокальной корковой активности, вносящей вклад в наши топографические и декодирующие результаты.FFA с акцентом на правом полушарии (Kanwisher et al., 1997) и одинаково двусторонне распределенный PPA (Epstein and Kanwisher, 1998), в принципе, предсказывают дифференциальное альфа-распределение в коже черепа и, возможно, более низкую альфа-мощность в целом по правой затылочной кости при посещении лиц. Наша альфа-топография посещаемости минус посещаемость в целом соответствовала этому прогнозу (рис.3 A ), и эта модель отличалась от графика на графике разницы посещаемости минус посещаемости и инструментов (рис.3 В ). Однако мы надеемся прояснить, что мы не предлагаем локализовать лежащие в основе корковые генераторы регистрируемой активности кожи головы с помощью методов, которые мы здесь использовали; поэтому мы обратились к декодированию.
Наш анализ декодирования убедительно подтверждает утверждение о том, что внимание модулирует альфа-топографии в зависимости от категории объекта и согласуется с временными ходами различий в альфа-образцах, наблюдаемых на графиках топографических различий скальпа.В нашем анализе декодирования статистически значимая точность декодирования с высокой вероятностью обеспечивает прямое свидетельство того, что альфа-топография содержит информацию о выбранной категории объекта, и, следовательно, что внимание, основанное на объектах сверху вниз, модулирует альфа-топографию в соответствии с категорией объекта, на который указывают (обслуживаемые) . Мы наблюдали, что статистически значимое декодирование происходило в диапазоне 500-800 мс после спасения / предварительной цели, что указывает на то, что паттерны альфа-топографии на коже черепа надежно модулировались нашим манипулированием вниманием в этом временном диапазоне (рис.4). Важно отметить, что диапазон 500–800 мс соответствует периодам на графиках альфа-топографических разностей, где изображения стабилизировались.
Чтобы проверить, были ли наши результаты декодирования специфичными для альфа-диапазона, мы выполнили ту же процедуру декодирования SVM для мощности в тета-, бета- и гамма-диапазонах и не обнаружили значительного превосходного декодирования в период ожидания для этих полосы частот (рис. 5). Этот результат согласуется с гипотезой о том, что осцилляторная нейронная активность в альфа-диапазоне механически участвует в упреждающем внимании, тогда как активность в других частотных диапазонах ЭЭГ не модулируется в соответствующих целевых визуальных областях ЭЭГ человека.
В двух последующих экспериментах мы непосредственно оценили две альтернативные интерпретации наших результатов декодирования из эксперимента 1. Во-первых, различия в альфа-топографии скальпа после спасения могут отражать чисто сенсорную обработку, связанную с каждым сигналом (например, треугольник против круга). Это должно быть применимо только к декодированию с высокой вероятностью (хотя и не значимым в наших тестах), наблюдаемому в ранний период после спасения (∼0–200 мс) на рисунке 4, а не к декодированию с более длительной задержкой.Действительно, мы проверили это в эксперименте 2, в котором участники выполняли ту же задачу и видели те же сигналы и цели, что и в эксперименте 1, но форма сигнала не предсказывала предстоящую категорию объекта. Мы наблюдали статистически значимое декодирование в период после спасения / предварительной цели от 0 до 200 мс, связанное с физическими функциями реплики (Bae and Luck, 2018), но не было значимого декодирования позже в интервале от реплики к цели.
Второе альтернативное объяснение наших результатов декодирования из эксперимента 1 состоит в том, что они были вызваны различиями в наборах задач в зависимости от условий объекта.Задача для лиц, например, заключалась в различении пола, в то время как для сцен — различать городские и естественные сцены, оставляя открытой возможность того, что наше декодирование в конце периода после спасения отражало различия в поставленных задачах (Hubbard et al., 2019 ), а не контроль внимания над выбором объекта, как мы предлагаем. Мы можем отклонить эту альтернативу на основе результатов эксперимента 3, в котором реплики предсказывали соответствующий целевой объект, но задача распознавания была одинаковой для всех категорий объектов: различать, был ли объект, на который была подана подсказка, был в фокусе или размыт.Таким образом, мы смогли воспроизвести подготовительные эффекты внимания, связанные с альфа-связью с большей задержкой, о которых сообщалось в эксперименте 1, контролируя факторы набора задач.
Наши результаты показывают, что альфа-модуляция ЭЭГ связана с избирательным вниманием на основе объектов, расширяя предыдущие выводы о том, что альфа-модуляция связана с вниманием к пространственным местоположениям и визуальным особенностям низкого уровня. Используя подход декодирования SVM, мы выявили различия в топографических паттернах мощности альфа-канала во время выборочного внимания к разным категориям объектов.Кроме того, мы связали временной диапазон, в течение которого было достигнуто статистически значимое декодирование, с топографическими картами с усилением альфа-канала и обнаружили, что альфа-модуляция согласуется с временным ходом подготовительного внимания, наблюдаемым в предыдущих исследованиях. В целом, эти результаты подтверждают модель, согласно которой нейронная активность в альфа-диапазоне функционирует как модулятор внимания сенсорной обработки как для зрительных функций низкого уровня, так и для нейронных репрезентаций высокого порядка, например, для объектов.
Сноски
Эта работа была поддержана грантом Mh217991 на имя G.Р.М. и M.D. S.N. поддерживался T32EY015387. Мы благодарим Майкла Дж. Тарра, Центр нейронных основ познания и Департамент психологии Университета Карнеги-Меллона (http://www.tarrlab.org/) за изображения стимулов на лице при финансовой поддержке премии Национального научного фонда 0339122. Мы также благодарим Стивена Дж. Лака и Ги-Йеула Бэ за советы по анализу с использованием методов декодирования, а также Атиша Кумара и Тамима Хассана за помощь в сборе данных.
Авторы заявляют об отсутствии конкурирующих финансовых интересов.
- Корреспонденция должна быть адресована Джорджу Р. Мангуну на grmangun {at} ucdavis.edu
ReactionCode: формат для поиска, анализа, классификации, преобразования и кодирования / декодирования реакции | Journal of Cheminformatics
Формат ReactionCode
Структура
ReactionCode — это многослойный машиночитаемый код, который создается путем объединения реагентов и продуктов в сжатый график реакции (CGR) (рис. 1). Код реакции состоит из трех блоков, каждый из которых содержит соответствующие уровни:
- .
1.
Блок 1: реакционный центр, содержащий только атомы, в которых происходит изменение статуса связи (изменения стереохимии, заряда, изотопа или статуса радикала не квалифицируют атом как часть реакционного центра
- 2.
Блок 2: Атомы вокруг реакционного центра, оставшиеся в продукте
- 3.
Блок 3: Оставление атомов вокруг реакционного центра (если есть)
Каждый слой состоит из основного подслоя и до трех дополнительных подслоев, которые описывают стереохимию, заряды и изотоп, соответственно. Слой начинается с номера, если он иллюстрирует реакционный центр или оставшуюся группу, или с буквы, если он описывает уходящую группу.Он всегда заканчивается символом «|».
Главный подуровень Главный подуровень состоит из 4 типов информации: глубины, кода атома, таблицы соединений и стехиометрии атома (рис. 2). Этот слой начинается с глубины, за которой следует «:». Глубина указывает расстояние относительно реакционного центра. Он выражается цифрами для реакционного центра и оставшейся группы (групп) и буквами для уходящей группы (групп). Код атома состоит из трех символов: первый указывает наивысший статус связанных связей, закодированных в шестнадцатеричной системе (дополнительный файл 1: таблица S7), два других кодируют тип атома (дополнительный файл 1: таблица S8).За каждым кодом атома следует заключенная в скобки таблица соединений, которая указывает каждую связь, связанную с атомом с более низким индексом. Связь кодируется 4 символами: 1-й указывает порядок связи в реагентах, 2d кодирует порядок связи в продуктах (Дополнительный файл 1: Таблица S6), а последние два относятся к индексу другого подключенного атома. Индексы кодируются в шестнадцатеричной системе для подключаемых атомов, которые присутствуют в блоках, соответствующих уходящей группе (Дополнительный файл 1: Таблица S2), а индексы атомов в двух других блоках кодируются с использованием таблицы поиска (Дополнительная файл 1: Таблица S1).Наконец, квадратные скобки хранят стехиометрию атома, то есть, сколько раз один и тот же атом был в продуктах (пример в дополнительном файле 1: рисунок S1).
Рис. 3Необязательная композиция подслоя: Необязательный подслой расположен непосредственно после основного подслоя. Такой код состоит из символа «/», за которым следует буква, и указывает модификацию (/ c для заряда, / i для изотопа и / s для стереохимии). Каждый блок, определяющий атом или связь, состоит из четырех символов.Первые два символа — это число (2 символа), обозначающее индекс (десятичная система) объекта (атома или связи) в текущем слое, который необходимо изменить. Следующие 2 символа кодируют изменение, применяемое к реагентам (первый символ) и продуктам (второй символ) (для изотопов и заряда см. Дополнительный файл 1: Таблица S3; для стереохимии атомов см. Дополнительный файл 1: Таблица S4; и для стереохимии связей. , см. Дополнительный файл 1: Таблица S5)
Рис. 4Процесс кодирования и декодирования: Кодирование Реагенты и продукты отображаемой реакции объединяются в псевдомолекулу.Изменения облигаций аннотируются: зеленым — изменение порядка облигаций, синим — сделанная облигация, а красным — разорванная облигация. Все атомы и связи аннотированы как часть реакционного центра (внутри синего круга), оставаясь в конечном продукте (зеленые кружки) или оставляя конечный продукт (желтый кружок). Наконец, все атомы и связи кодируются в ReactionCode слоями, начиная от реакционного центра до самого внешнего слоя. Декодирование: Код реакции преобразуется в псевдомолекулу, которая позволяет восстановить начальную реакцию.
Необязательные подслои Необязательные подслои определяют атом и связь в соответствующем слое.Только подслой (и), где атом имеет свойство, отличное от эталона 0 (т.е. имеет заряд, информацию о стереохимии, нестандартный изотоп или является радикалом), записываются непосредственно после конца основного подуровня. слой. Приоритетный порядок следующий: (1) подслой заряда (/ c), (2) подслой стереохимии (/ s), (3) изотопный подслой (/ i) и (4) радикал подслой (/ r) (рис. 3).
- 1
Уровень заряда: Уровень заряда начинается с / c, а информация о заряде содержится в блоке, содержащем индекс заряженного атома (2 цифры) и 2 символа, кодирующие заряд.Первый кодирует состояние в реагентах, а второй — в продуктах (Дополнительный файл 1: Таблица S3). Например, в / c00HH «/ c» указывает, что этот слой содержит информацию о заряде. Наличие 4 символов означает, что 1 (4/4) атом имеет заряд. Единственная модификация: «00HH». 00 означает, что объект с индексом 00, который является атомом «008», изменен. Третий символ «H» кодирует отрицательный заряд \ (- 1 \), который остается неизменным в продуктах, поскольку четвертый символ кодируется той же буквой «H».
- 2
Слой стереохимии: Слой стереохимии начинается с / s, и относительная информация содержится в блоке, содержащем индекс атома или связи (2 цифры), который имеет соответствующую модификацию стереохимии и 2 символа, кодирующие стереохимию в реагентах первым символом и в продуктах по второму (Дополнительный файл 1: Таблицы S4 и S5).например, в / s01640364, «/ s» указывает, что этот слой содержит информацию о стереохимии. Наличие 8 символов означает, что 2 (8/4) объекта [атом (ы) и / или связь (и)] имеют информацию о стереохимии. Это две модификации: «0164» и «0346». Первая модификация кодируется первыми 4 символами «0164». 01 означает, что объект с индексом 01, то есть облигация «11GV», изменен. Третий символ «4» кодирует связь ВНИЗ в реагентах, которая становится связью ВВЕРХ в продуктах, обозначенных четвертым знаком «6».Следующие 4 символа 0364 изменяют связь «11GU» с UP на DOWN.
- 3
Изотопный слой: изотопный слой начинается с / i, а информация об изотопе содержится в блоке, содержащем индекс атома изотопа (2 цифры) и 2 символа, кодирующие разность масс между текущим изотопом и эталоном. Первый — для реагентов, второй — для продуктов (Дополнительный файл 1: Таблица S3).{18} \) О. Четвертый символ «H» не изменился, что указывает на то, что атомы в продуктах остаются одним и тем же изотопом.
- 4
Радикальный слой: изотопный слой начинается с / r, а информация об изотопе содержится в блоке, содержащем индекс атома изотопа (2 цифры) и 2 символа, кодирующие разность масс между текущим изотопом и эталоном.Первый — для реагентов, второй — для продуктов (Дополнительный файл 1: Таблица S3). например, в / r00IJ «/ r» указывает, что этот слой содержит информацию об изотопах. Наличие 4 символов означает, что 1 (4/4) атом является радикальным. Модификация — «00IJ». 00 означает, что объект имеет индекс 00 на текущем подуровне. Третий символ «I» кодирует добавление 1 радикала (валентность углерода равна 1). Четвертый символ «J» кодирует добавление 2 радикалов (валентность углерода равна 2).
Процесс кодирования / декодирования
Одной из основных сильных сторон ReactionCode является его способность быть двунаправленной: реакцию, закодированную в ReactionCode, можно легко частично или полностью декодировать, чтобы вернуть реакцию (рис. 4).
Рис. 5Алгоритм кодирования ReactionCode: После того, как все атомы и связи закодированы, все закодированные атомы, присутствующие в реакционном центре (глубина = 0), сортируются в обратном порядке.Если два или более атомов имеют одинаковый код, запускается алгоритм разрешения конфликтов. Алгоритм конфликта построит дерево связанного атома (см. Дополнительный файл 1: Рисунок S2) и сравнит коды атома и коды связи атома, присутствующего в следующем слое, с использованием алгоритма BFS. Алгоритм повторяется до тех пор, пока конфликты не будут разрешены и не будет установлен надлежащий порядок. Затем устанавливаются связи между атомами в текущем слое. Затем все атомы, присутствующие на глубине n + 1 (если они есть), которые будут всеми атомами, связанными с атомами в реакционном центре в этой ситуации, сортируются в обратном порядке.Если есть какие-либо конфликты, они сначала решаются путем сравнения положения связанных атомов в предыдущем слое, затем с использованием связанных связей, свойств атома (стереохимия, заряд и изотопия) и, наконец, в следующем слое (ах), если конфликт не может быть разрешен. Мы повторяем этот процесс до тех пор, пока не будут обработаны все слои.
Рис. 6ReactionCode частичное и полное декодирование: ReactionCode может быть декодирован путем взятия всех или некоторых слоев. Слой 0 соответствует декодированию только реакционного центра.Слои 0 + 1 иллюстрируют декодирование реакционного центра и всех окружающих атомов в оставшейся группе, имеющей глубину, равную 1, в то время как слои 0 + 1 + A включают все окружающие атомы (оставшиеся и уходящие группы) с глубиной 1. Слои 0 + 1 + 2 и 0 + 1 + 2 + A + B рассматривают все окружающие атомы, присутствующие на глубине, меньшие или равные 2. Слои 0 + 1 + 2 + 3 + 4 + 5 — это пример, в котором реакция декодируется. целиком, но без уходящей группы. Наконец, «Все слои» представляют собой декодирование полной реакции.
Для того, чтобы сгенерировать ReactionCode, необходима отображенная реакция.Первый шаг состоит в аннотировании каждого атома и связи в реагентах и продуктах. Вычисляются три типа аннотации:
атомов и связей, составляющих реакционный центр
атомов и связей присутствуют как в реагентах, так и в продуктах, которые обозначены как оставшаяся группа
атомов и связей, присутствующих в реагентах, но отсутствующих в продуктах (если есть), которые помечены как уходящая группа
После завершения части аннотации реагенты и продукты объединяются в CGR.Наконец, ReactionCode генерируется из CGR. Каждый атом CGR кодируется и ранжируется в обратном порядке по уровням. Алгоритм начинается с реакционного центра, ранжирует каждый атом этого слоя в обратном порядке и устанавливает связь между ними. Затем алгоритм поиска в ширину (BFS) используется для получения всех окружающих атомов, имеющих глубину 1. Эти атомы разделены на 2 слоя: те, которые принадлежат оставшемуся слою, и те, которые являются частью уходящей группы. Все закодированные атомы ранжируются в обратном порядке, и устанавливаются связи между каждым атомом с текущим и предыдущим слоями.Алгоритм повторяет эту процедуру до тех пор, пока все атомы не будут посещены (рис. 5).
Процесс декодирования восстанавливает псевдомолекулу из кода реакции, преобразовывая каждый атомный код в атомный объект и создавая связи между ними. Этот шаг основан на библиотеках Java хемоинформатики, содержащихся в CDK (Chemistry Development Kit) [31]. Затем псевдомолекула превращается в реагенты и продукты, чтобы вернуть исходную реакцию. Реакционный код настроен по умолчанию для восстановления сбалансированной реакции, но элементы, присутствующие в блоке уходящей группы, могут игнорироваться пользователем, чтобы не иметь их в продуктах.
Программа ReactionCode
Java на базе CDK использовалась для разработки программного обеспечения для генерации ReactionCode, его декодирования, создания псевдомолекул и использования в качестве нового языка преобразования. Все эти функции можно легко использовать благодаря CLI (интерфейсу командной строки), а файл JAR также можно напрямую использовать в качестве API, вызывая соответствующий класс.
Кодировщик Кодер позволяет создавать псевдомолекулы и коды реакции. В качестве входных данных он принимает наиболее распространенные форматы: SMIRKS (одиночный или набор SMIRKS в файле), RXN и RDF.Кодировщик может предоставлять псевдо-улыбки в формате SDF и SMILES и отображать их. Наконец, сгенерированные коды реакции представлены в файле CSV.
Декодер Декодер позволяет вернуть исходную реакцию. Реакции могут быть представлены как responseSMILES, SMIRKS, RXN или RDF. Их также можно отобразить как файл PNG. Кроме того, частичную реакцию можно вызвать, задав интересующие слои в качестве входных данных (рис. 6).
Transformer Благодаря структуре ReactionCode, где каждый уровень зависит только от своих предыдущих слоев, но не зависит от его последующих уровней, его можно использовать в качестве языка преобразования, где ReactionCode преобразуется в шаблон, применяемый к набору реагенты (рис.6). Преобразователь принимает полный или частичный код реакции (набор слоев) и реагенты в виде уникальной строки SMILES или файла SD. Если весь шаблон соответствует структурам запроса, преобразователь сгенерирует все уникальные возможные продукты. Он может выводить их в формате responseSMILES, SMIRKS, RXN или RDF.
Проверка кода реакции
Для тестирования кодирования и декодирования мы использовали набор данных UPSTO (https://bitbucket.org/dan2097/patent-reaction-extraction/downloads). Во-первых, все молекулы-зрители (т.е. молекулы, не участвующие в реакции) были удалены. Затем все реакции были закодированы в ReactionCode. Круглый отпечаток ECFP6 был создан для каждой молекулы в обеих реакциях. Реакция считалась аналогичной, если все отпечатки исходной реакции содержались в отпечатках декодированной реакции. Чтобы оценить правильность ответов, признанных неидентичными, мы применили 3 следующих протокола:
Молекулы не были кекулированы, и продукты не корректировались.Все ароматические связи были установлены как одиночные, а ароматические свойства были установлены как ложные. Неявный водород был установлен на 0 для каждого ароматического атома. Все ароматические атомы были установлены как неароматические. Мы не применяли наш алгоритм, пытаясь вывести недостающие расщепленные связи для несбалансированных реакций, чтобы восстановить правильный баланс, предсказывая правильный недостающий продукт. Эта процедура позволяет обнаружить неправильное сопоставление атом-атом в наборе данных USPTO путем ручного сравнения возвращенных результатов. Изображаются как исходная, так и декодированная реакции, а отображение атом-атом проверяется в исходной реакции.Удаление ароматичности и отказ от кекулизации молекул позволяет избежать ложноотрицательных результатов из-за кекулизации, которая может привести к образованию различных таутомеров.
Молекулы были кекулированы, а продукты не исправлены. Все молекулы были кекулированы. Мы не применяли наш алгоритм, пытаясь вывести недостающие расщепленные связи для несбалансированных реакций, чтобы восстановить правильный баланс, предсказывая правильный недостающий продукт. Эта процедура обнаружит различия, связанные с кекулизацией, ведущей к потенциально различным таутомерам, а также сбои нашего алгоритма коррекции продукта.
Молекулы не кекулировались, продукты корректировались. Все ароматические связи были установлены как одиночные, а ароматические свойства были установлены как ложные. Неявный водород был установлен на 0 для каждого ароматического атома. Все ароматические атомы были установлены как неароматические. Мы применили наш алгоритм, пытаясь вывести недостающие разорванные связи для несбалансированных реакций, чтобы восстановить правильный баланс, предсказывая правильный недостающий продукт. Эта процедура обнаружит различия, связанные с отказами нашего алгоритма исправления продукта.
Код процедуры проверки можно найти на GitHub (Tests.java).
Таблица 1 Валидация ReactionCode (протестировано с версией 1.2.0)Оценка информационного содержания сигналов ERP при шизофрении с использованием методов многомерного декодирования
Основные моменты
- •
В этом исследовании использовались методы многомерного декодирования, которые широко используются для оценить природу нейронных репрезентаций у нейротипичных людей и применить их для сравнения людей с шизофренией и соответствующих контрольных субъектов.
- •
Участники выполнили задачу визуальной рабочей памяти, которая требовала запоминания 1–5 элементов с одной стороны дисплея и игнорирования равного количества элементов с другой стороны дисплея.
- •
Мы попытались декодировать, какая сторона хранится в рабочей памяти, исходя из распределения активности ERP на коже черепа в течение периода задержки задачи рабочей памяти, и мы обнаружили более высокую точность декодирования у людей с шизофренией, чем в контрольной группе. субъектов, когда в памяти хранился единственный предмет.
- •
Эти результаты подтверждают гипотезу гиперфокусировки когнитивной дисфункции при шизофрении и являются важным доказательством концепции применения методов многомерного декодирования для сравнения нейронных репрезентаций в психиатрических и непсихиатрических популяциях.
Реферат
Методы многомерной классификации (декодирования) паттернов обычно используются для изучения механизмов нейрокогнитивной обработки у типичных людей, где их можно использовать для количественной оценки информации, содержащейся в нейронных сигналах с одним участником.Эти методы декодирования также потенциально полезны для определения различий в представлении информации между психиатрическими и непсихиатрическими группами населения. Здесь мы исследовали ERP от людей с шизофренией (PSZ) и здоровых контрольных субъектов (HCS) в задаче на рабочую память, которая включала запоминание 1, 3 или 5 элементов с одной стороны дисплея и игнорирование другой стороны. Мы использовали пространственный образец ERP, чтобы декодировать, какая сторона дисплея хранится в рабочей памяти. Можно было бы ожидать, что точность декодирования неизбежно будет ниже в PSZ в результате увеличения шума (т.е.е., большая вариабельность от испытания к испытанию). Однако мы обнаружили, что точность декодирования была выше в PSZ, чем в HCS при загрузке памяти 1, что согласуется с предыдущими исследованиями, в которых сигналы ERP, связанные с памятью, были больше в PSZ, чем в HCS при загрузке памяти 1. Мы также заметили, что точность декодирования была сильно связано с соотношением активности ERP, связанной с памятью, и уровня шума. Кроме того, мы обнаружили схожие уровни шума в PSZ и HCS, что противоречит ожиданиям, что PSZ будет демонстрировать большую изменчивость от испытания к испытанию.Вместе эти результаты демонстрируют, что методы многомерного декодирования могут быть корректно применены на уровне отдельных участников для понимания природы нарушения когнитивных функций в психиатрической популяции.
Ключевые слова
ERP-декодирование
Рабочая память
Шизофрения
Рекомендуемые статьиЦитирующие статьи (0)
Просмотреть аннотацию© 2020 Авторы. Опубликовано Elsevier Inc.
Рекомендуемые статьи
Цитирующие статьи
Decoding Boys, Cara Natterson: 9781984819055
Похвала
«Мы знаем, что мальчикам нужна наша поддержка, чтобы они росли в безопасности, здоровыми, счастливыми и эмоционально цельными.Но как мы можем этого добиться, столкнувшись с их юношеским молчанием? Decoding Boys спешат на помощь! Практическое, мудрое понимание (подкрепленное точными науками) доктора Наттерсона о развитии молодых людей является абсолютно необходимым чтением для любого, у кого в жизни есть мальчик! » —Пегги Оренштейн, автор книги Boy & Sex
« Decoding Boys предлагает замечательное научное понимание того, почему мальчики-подростки, кажется, закрываются и ведут себя антисоциально, когда они вступают в половую зрелость.Мы бы сказали, что хотели бы, чтобы эта книга была рядом, когда мы были подростками, но мы были слишком заняты видеоиграми, выпивкой несовершеннолетних и лжи родителям, чтобы читать ». —Ник Кролл и Эндрю Голдберг, соавторы Big Mouth
«Пятьдесят лет назад публикация книги« Наши тела, мы сами »подняла женщин, заменив невежество и предрассудки на знания и силу сестринства. Программа «Decoding Boys» также революционна в своей миссии — помочь нам понять нюансы развития мальчиков.Теплый, откровенный и разговорный стиль Наттерсона дает нам яркое, переливчатое и глубокое погружение в их эмоциональный и физический рост; ее голос властный и страстный. Я закончила читать эту книгу, просветленная и взволнованная, чтобы поделиться ею с родителями мальчиков во всем мире ». — Венди Могел, доктор философии, автор бестселлера New York Times «Благословение обтянутого колена» и «Благословение B минус»
«Decoding Boys развенчивает широко распространенный миф о загадочном мальчике-подростке.Доктор Кара Наттерсон освещает внутреннюю жизнь мальчиков, подробно описывает давление, с которым они сталкиваются со стороны внешнего мира, и учит родителей, как эффективно вовлекать и поддерживать своих сыновей-подростков. Decoding Boys — это ясно, мудро и открывает глаза. Если вы воспитываете мальчика, вам нужна эта блестящая книга ». — Лиза Дамур, доктор философии, автор бестселлеров New York Times « Untangled and Under Pressure»
«Для каждого родителя, который спрашивает меня, как заставить своего сына сказать больше, чем« Я в порядке », я сейчас есть ответ: прочитайте Decoding Boys и примите мудрые, вдумчивые, сострадательные и информированные советы Кары Наттерсон.Это даст родителям возможность улучшить отношения со своими сыновьями и поможет им стать уверенными и достойными молодыми людьми ». —Розалинд Уайзман, New York Times автор бестселлеров Queen Bees and Wannabes
« Decoding Boys — это полное руководство, которое поможет вам понять и воспитать своих мальчиков с принятием и перспективой. Читать ее — все равно что иметь чуткого, действительно умного друга, который полностью понимает то, через что вы проходите, и помогает на каждом этапе! » —Маллика Чопра, автор книги Living with Intent
«Decoding Boys — это книга, которую мы так долго ждали! ДокторКара Наттерсон занимается темами, которые трудно понять родителям, не говоря уже о том, чтобы обсуждать их со своими детьми. Она демистифицирует сложную науку о половом созревании мужчин и дает разумные советы любому взрослому, живущему с все более молчаливым мальчиком-подростком и желающим поддержать его ». — Луиза Гринспен, доктор медицины, соавтор книги «Новое половое созревание: как управлять ранним развитием у современных девочек»
.